"拡散方式"の新顔は、日本語OCRの王者に挑めるのか —— DiffusionGemmaを4エンジン対決に加えてみた
"拡散方式"の新顔は、日本語OCRの王者に挑めるのか —— DiffusionGemmaを4エンジン対決に加えてみた

日本語OCRの検証も、今回で4回目になりました。
これまで、YomiToku・Gemini・Claudeという3つのエンジンに、まったく同じ画像を読ませて精度を比べてきました。結果は……と言いたいところですが、もう少し伏せておきます。ひとつだけ言えるのは、「文字を読む力」と「レイアウトを理解する力」は、どうやら別物らしい、ということでした。
そんな折、気になる新しいモデルが登場しました。Google DeepMindの「DiffusionGemma」です。これまでのモデルが文字を1つずつ順番に書き出す"自己回帰"方式なのに対して、こちらは画像生成でおなじみの"拡散"方式で文章を組み立てるという、少し毛色の違うアプローチを採っています。売りは、とにかく生成が速いこと。
ただ、このモデルには公開APIがありません。つまり、自分でGPUを借りて動かすしかない。——そして、その「動かすまで」が、今回いちばんの山場になりました。
新方式の挑戦者は、これまでの王者に届くのか。4つ目のエンジンを加えた、日本語OCR対決の最終戦です。
今回の挑戦者「DiffusionGemma」って何者?
DiffusionGemmaは、Google DeepMindが公開したオープンモデルです。これまで検証してきたGeminiやClaudeとは、文章の「作り方」が根本的に違います。
普通の言語モデルは、文章を左から右へ、1トークンずつ順番に書き出していきます(自己回帰方式)。これに対してDiffusionGemmaは、画像生成AIでおなじみの"拡散"の考え方を文章に持ち込んでいて、ある程度のかたまり(ブロック)をまとめて、ノイズだらけの状態から少しずつ整えていくように生成します。この仕組みのおかげで、1回の処理で複数トークンを同時に確定でき、生成がとても速い——これがこのモデルの最大のウリです。
そしてもうひとつ大事なのが、テキストだけでなく画像も受け取れるマルチモーダルモデルだという点。だからこそ、今回のOCR検証の土俵に上がれるわけです。画像を渡して「読んで」とお願いできる、という意味では、GeminiやClaudeと同じ使い方ができます。
ただ、GeminiやClaudeのように「APIキーを1本もらえばすぐ呼べる」ホスト型のサービスは、執筆時点では用意されていません。モデルの重み自体は公開されているので、使いたければ自分でGPUを用意して動かすことになります。……この「自分で動かす」が、想像以上のひと山でした。次の章で、その顛末を正直に書きます。

動かすまでが、ひと山でした
DiffusionGemmaには、これまでのGeminiやClaudeと違って、気軽に叩ける公開APIがありません。モデルの重みは公開されているので、要は「自分でGPUを用意して、自分で動かす」必要があります。
当初の計画はシンプルでした。クラウドでA100(80GB)を時間借りして、vLLMという定番の推論サーバーに載せるだけ——のはずでした。vLLMは高速な推論で広く使われていて、公式の手順も用意されています。これは楽勝だろう、と。
ところが、ここからが長かったのです。
最初に当たったGPUは、入っているドライバが古く、vLLMがうまく起動してくれませんでした。クラウドGPUはホストごとにドライバのバージョンがまちまちで、どうやら相性の悪いホストを引いてしまったようです。そこで「次は、ドライバが新しいかどうかを先に確かめる」と決め、CUDA 12.8以降を指定してPodを取り直しました。新しく確保したA100は、ドライバ575.57.08。ここでようやく、土台が整いました。
ところが、それでも一筋縄ではいきませんでした。DiffusionGemmaは公開されたばかりで、vLLMの最新版がまだこの新しいモデルに安定して噛み合ってくれません。最終的に、vLLM経由はいったん諦めました。代わりに、Transformersから直接モデルを呼び出す素朴なやり方に切り替えたところ、ようやく素直に動いてくれました。遠回りはしましたが、出力の形式は他の3エンジンと完全に同じに揃えてあるので、このあとの採点(CER比較)の公平性は保たれています。
(余談ですが、最初はAWSで動かすつもりでした。ただ、GPUの利用上限を引き上げる申請が審査待ちで間に合わず、すぐに借りられたRunPodへ切り替えました。この「とにかく動かせる環境を探す」感じも、新しいモデルならではかもしれません。)
かかった費用は、環境構築の試行錯誤も込みで、合計およそ420円。時間は数時間でした。お金の面では拍子抜けするほど安かったのですが、本当のコストはお金ではなく、「動かすまでの時間」の方にありました。
……ここまで読んで、おや、と思われた方もいるかもしれません。DiffusionGemmaの売りは「生成の速さ」のはず。その速いはずのモデルを、動かすまでにこれだけ手間取った。この皮肉については、最後にもう一度ふれます。

検証の設計
検証のやり方は、これまでと同じものを使い回しています。シリーズを続けてきた強みは、ここにあります。
読ませる画像は、おなじみの4枚です。
① 縦書き —— 縦組みの短い文章
② 請求書 —— 表組みを含む定型文書
③ 多段組み —— 左右2段に分かれたレイアウト
④ 低解像度 —— わざと解像度を落とした、にじんだ画像
公平を期すため、4つのエンジンにはまったく同じ画像を、一字一句同じプロンプトで渡しています。各画像は独立したリクエストで処理し、前の結果を引きずらないようにしました。DiffusionGemmaだけは、前章のとおり自前のGPU(A100 80GB)で動かしています。
採点には**CER(文字誤り率, Character Error Rate)**を使います。正解のテキストと出力を比べて、何文字ぶん間違えたかの割合を出すもので、低いほど高精度です。比較がブレないよう、表記ゆれの影響を抑える前処理(空白の除去、表の記号の除去、全角・半角をそろえるNFKC正規化)をかけたうえで、全エンジンを同じ物差しで採点しています。
なお、採点にはひとつだけ注意点があるのですが、それは結果のところで正直にお話しします。
DiffusionGemmaに、4枚を食わせてみる
環境さえ整えば、あとはこれまでと同じです。縦書き・請求書・多段組み・低解像度——おなじみの4枚を、他の3エンジンと一字一句同じプロンプトで読ませていきます。1枚ずつ、順番に見ていきましょう。
① 縦書き —— いきなり good な滑り出しでした。文字誤り率(CER)は0.8%。ほんのわずかな取りこぼしだけで、ほぼ完璧に読めています。縦組みの日本語をここまで素直に処理できるのは、正直なところ意外でした。新方式とはいえ、文字を「読む」基礎体力はしっかりある、という第一印象です。

② 請求書 —— こちらは数字の上では47%前後と、少し悪く見えます。ただ、これは文字そのものを読み間違えているというより、「どの順番で項目を拾うか」という読み順のズレが主な原因です(この点は全エンジンに共通して効いているので、あとでまとめて説明します)。文字認識そのものは、ここでも安定していました。
③ 多段組み —— ここで、つまずきます。CERは75%。出力を見ると、左右の段を行ったり来たりしながら、文章が混ざってしまっていました。……この崩れ方、どこかで見た覚えがあります。そう、前回Geminiが、そしてその前にYomiTokuが見せたのと、ほとんど同じ"混線"でした。読む方式が新しくなっても、複数段のレイアウトを正しく追う、という壁は越えられなかったようです。

④ 低解像度 —— わざと解像度を落としたこの1枚は、50.4%。さすがに楽な相手ではありませんでしたが、ここで小さな見どころがありました。実は同じ画像で、Geminiは57.2%。つまりこの低解像度に関しては、新顔のDiffusionGemmaの方が、評判のGeminiよりわずかに上だったのです。
さて、1枚ずつの感触はつかめました。では、4つのエンジンを横に並べると、どう見えてくるのでしょうか。

4つを、並べてみる
ここで、4つのエンジンのスコアを一枚の表にまとめてみます。数字は文字誤り率(CER)で、低いほど高精度です。
エンジン | ①縦書き | ②請求書 | ③多段組み | ④低解像度 | 平均 |
|---|---|---|---|---|---|
Claude | 0.0% | 47.0% | 0.0% | 34.8% | 20.5% 🥇 |
DiffusionGemma | 0.8% | 47.3% | 75.0% | 50.4% | 43.4% |
Gemini | 0.0% | 47.0% | 75.0% | 57.2% | 44.8% |
YomiToku | 18.0% | 67.4% | 79.9% | 69.3% | 58.7% |
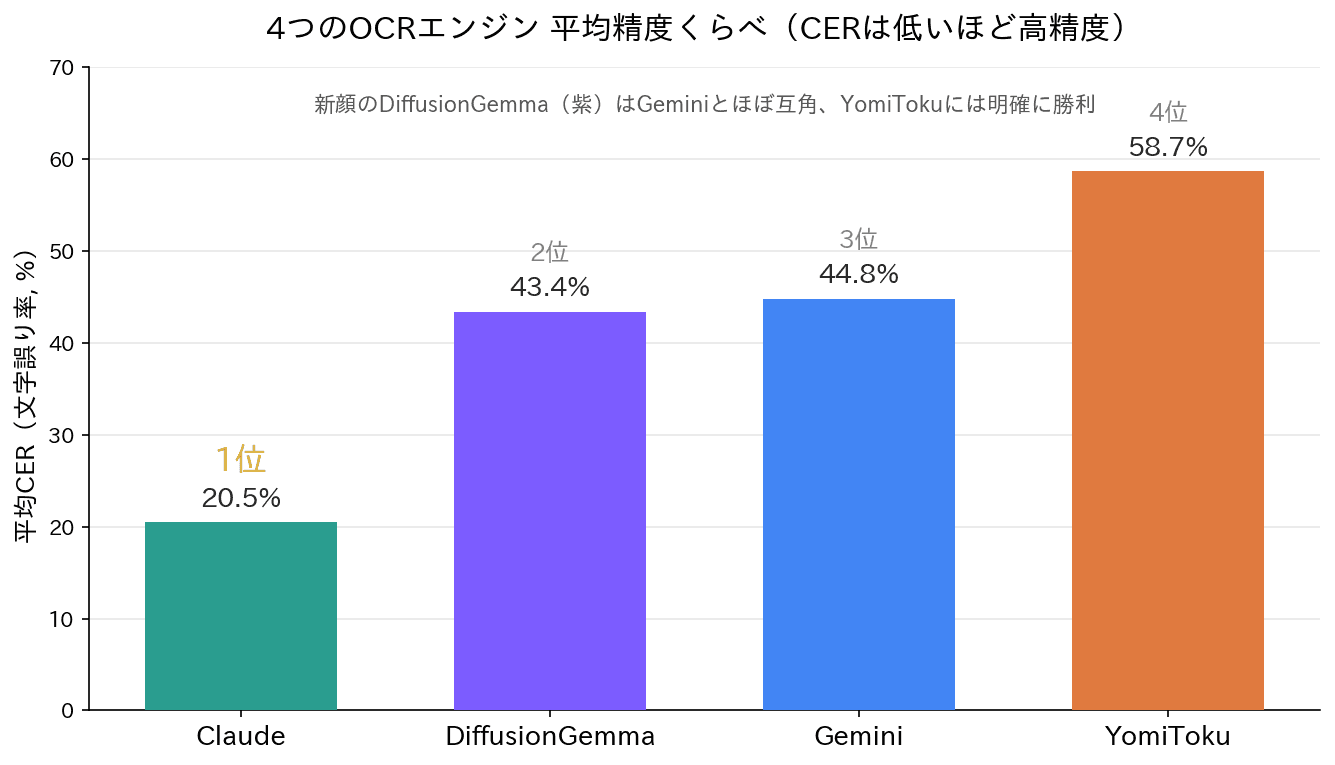
平均で見ると、Claudeが20.5%で頭ひとつ抜けています。続いてDiffusionGemmaが43.4%、Geminiが44.8%、YomiTokuが58.7%という並びになりました。新顔のDiffusionGemmaが、評判のGeminiをわずかに上回って2位につけた、というのは少し意外な結果です。
ただ、平均だけを見ていても、この検証のおもしろいところは見えてきません。画像ごとに分けて、棒グラフにしてみます。
こうして並べると、3つのことが浮かび上がってきます。
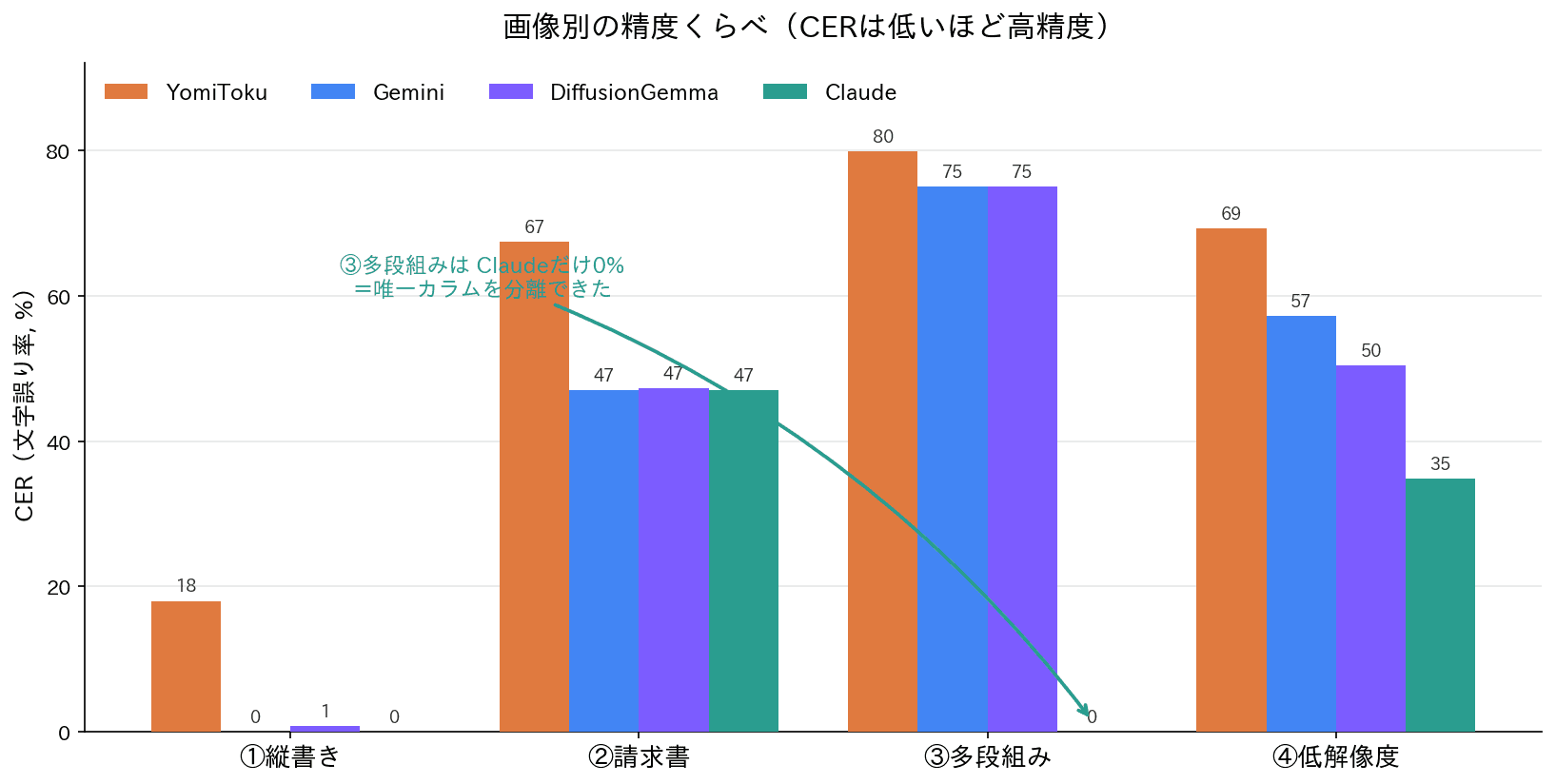
ひとつ目。 ①縦書きでは、Claude・Gemini・DiffusionGemmaの3つが、ほぼ0%でした。「文字を読む」だけなら、新顔も含めてVLM勢はどれも優秀で、差はほとんどありません。YomiTokuだけが18%と少し離されていますが、これも実用上は読める範囲です。
ふたつ目、そして最大の山場。 ③多段組みです。ここでは、Claudeだけが0%。残りの3つ——YomiToku・Gemini・DiffusionGemmaは、そろって75〜80%まで跳ね上がりました。先ほど見たとおり、左右の段が交ざる「混線」を起こしています。読む方式が拡散方式になっても、この壁は越えられませんでした。「文字を読む力」はみな高いのに、「レイアウトを理解する力」になると、依然としてClaudeだけが別格——前回からの主題が、4つ目のエンジンを加えても、そのまま当てはまったのです。

みっつ目。 ④低解像度では、Claudeが34.8%でやはり最も強く、その次にDiffusionGemma(50.4%)、Gemini(57.2%)と続きました。ぼやけた画像では、新顔のDiffusionGemmaが評判のGeminiを上回る場面もあった、という点は小さな見どころです。
②請求書の「47%」について(正直なところ)
ひとつ、表を見て「あれ?」と思われた方への補足です。②請求書だけ、ほぼ全員が47%前後で並んでいます。これは、4つのエンジンがそろって同じ誤読をした……わけではありません。
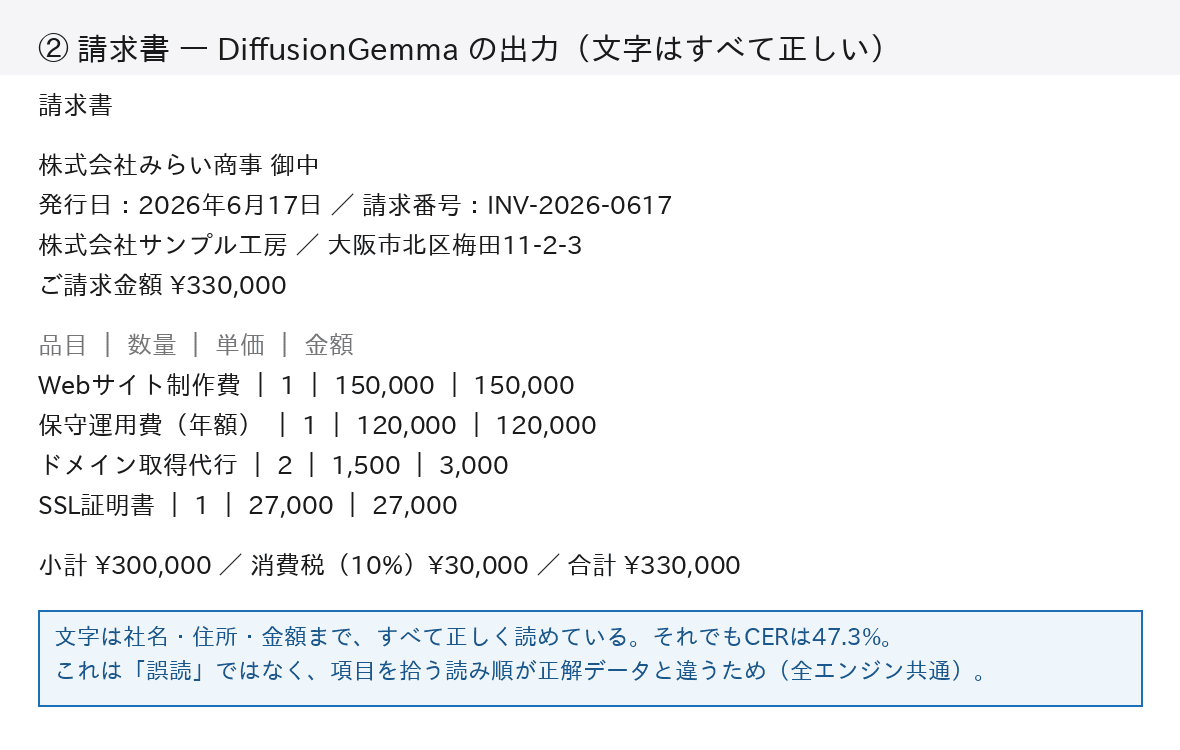
実際、②の出力(先ほどの画像)を見ると、社名も住所も金額も、文字はすべて正しく読めています。それでもCERが47%になるのは、項目を拾っていく「読み順」が、採点用の正解データと違っているためです。表組みの請求書では、人間でも「どの順で読むか」は割れます。
この差は全エンジンに等しく効いているので、順位の比較には影響しません。ただ、②の絶対値だけは「読み違いの多さ」ではなく「読み順のクセ」を表している——その点だけは、正直に断っておきます。
分かったこと
4つのエンジンを同じ土俵に並べてみて、見えてきたことを整理します。
1つ目。王者Claudeの強さは、4人目を加えても揺らがなかった。
平均20.5%という数字もさることながら、効いているのは③多段組みでただ一つ0%を出したことです。文字をどれだけ正確に読めるか——その点では、今やGemini・Claude・DiffusionGemmaの差はほとんどありません。「文字を読む」だけなら、VLMはどれを選んでもだいたい優秀、という時代になりました。差がつくのは、その先。「複数の段や複雑なレイアウトを、正しい順序で理解できるか」です。そして今のところ、そこで頭ひとつ抜けているのがClaude、という構図は今回も変わりませんでした。
2つ目。新顔のDiffusionGemmaは、なかなかの健闘だった。
平均ではGeminiをわずかに上回り、専用OCRのYomiTokuには明確に勝ちました。低解像度の画像では、評判のGeminiより上に出る場面もありました。拡散方式という新しい作り方でも、文字認識の地力は、既存のVLMにきちんと並んでいます。一方で、③多段組みではGeminiやYomiTokuと同じく混線しました。つまり、「新方式だからレイアウトも解ける」わけではない。文字を読む力と、レイアウトを理解する力は、生成の方式とは別の軸にある——今回いちばんの収穫は、この見立てが補強されたことかもしれません。
3つ目。"速さがウリ"のはずが、いまは「動かすまで」が最大のコストだった。
ここが、冒頭で予告した皮肉です。DiffusionGemmaの売りは生成の速さでした。ところが実務で触ってみると、その速さを味わう以前に、環境を整えて起動させるところでいちばん時間を使いました。出たばかりのモデルは、それを動かす周辺のソフトウェアがまだ追いついていない。これは性能の問題ではなく、エコシステムの成熟度の問題です。裏を返せば、APIキー1本ですぐ呼べて、しかも精度も高いホスト型サービス(今回でいうClaude)の「すぐ使える」という価値が、あらためて際立った検証でもありました。
実務的な落としどころをまとめると、こうなります。単段の定型文書をただ読むだけなら、もう専用OCRでもクラウドVLMでも大差ありません。選ぶ基準は「複雑なレイアウトを理解できるか」と「どれだけ手間なくすぐ使えるか」。前者を重く見るならClaude、コスト重視で単純な文書が中心ならGeminiクラスでも十分。そして拡散方式の新顔は、地力は本物ながら、本格的に使うのはもう少し環境が枯れてから——というのが、いまの正直な見立てです。
おわりに
これで、日本語OCRの検証は4回目になりました。1回目はYomiTokuの単体検証、2回目がYomiToku対Claude、3回目がClaude対Gemini、そして今回、新方式のDiffusionGemmaを加えて4つを横並びにしました。同じ4枚の画像と同じ採点を毎回使い回せたおかげで、エンジンが増えてもブレずに比べることができたと思います。
結論として、印字された文書をきれいに読むだけなら、選択肢はもうたくさんあります。本当の差は、レイアウトの理解と、導入のしやすさに出る。新しい拡散方式のモデルも、その地力は確かなものでした。あとは、それを誰もが気軽に動かせるようになる日を待ちたいところです。
さて、ここまでの4枚は、すべて「印字された」文書でした。次にやってみたいのは、もっと手強い相手——手書きです。崩れた手書き文字を相手にしたとき、専用OCRとVLM、そして拡散方式の新顔は、どこまで読めるのか。続きは、また手を動かしてみます。
日本語OCRの検証も、今回で4回目になりました。
これまで、YomiToku・Gemini・Claudeという3つのエンジンに、まったく同じ画像を読ませて精度を比べてきました。結果は……と言いたいところですが、もう少し伏せておきます。ひとつだけ言えるのは、「文字を読む力」と「レイアウトを理解する力」は、どうやら別物らしい、ということでした。
そんな折、気になる新しいモデルが登場しました。Google DeepMindの「DiffusionGemma」です。これまでのモデルが文字を1つずつ順番に書き出す"自己回帰"方式なのに対して、こちらは画像生成でおなじみの"拡散"方式で文章を組み立てるという、少し毛色の違うアプローチを採っています。売りは、とにかく生成が速いこと。
ただ、このモデルには公開APIがありません。つまり、自分でGPUを借りて動かすしかない。——そして、その「動かすまで」が、今回いちばんの山場になりました。
新方式の挑戦者は、これまでの王者に届くのか。4つ目のエンジンを加えた、日本語OCR対決の最終戦です。
今回の挑戦者「DiffusionGemma」って何者?
DiffusionGemmaは、Google DeepMindが公開したオープンモデルです。これまで検証してきたGeminiやClaudeとは、文章の「作り方」が根本的に違います。
普通の言語モデルは、文章を左から右へ、1トークンずつ順番に書き出していきます(自己回帰方式)。これに対してDiffusionGemmaは、画像生成AIでおなじみの"拡散"の考え方を文章に持ち込んでいて、ある程度のかたまり(ブロック)をまとめて、ノイズだらけの状態から少しずつ整えていくように生成します。この仕組みのおかげで、1回の処理で複数トークンを同時に確定でき、生成がとても速い——これがこのモデルの最大のウリです。
そしてもうひとつ大事なのが、テキストだけでなく画像も受け取れるマルチモーダルモデルだという点。だからこそ、今回のOCR検証の土俵に上がれるわけです。画像を渡して「読んで」とお願いできる、という意味では、GeminiやClaudeと同じ使い方ができます。
ただ、GeminiやClaudeのように「APIキーを1本もらえばすぐ呼べる」ホスト型のサービスは、執筆時点では用意されていません。モデルの重み自体は公開されているので、使いたければ自分でGPUを用意して動かすことになります。……この「自分で動かす」が、想像以上のひと山でした。次の章で、その顛末を正直に書きます。
動かすまでが、ひと山でした
DiffusionGemmaには、これまでのGeminiやClaudeと違って、気軽に叩ける公開APIがありません。モデルの重みは公開されているので、要は「自分でGPUを用意して、自分で動かす」必要があります。
当初の計画はシンプルでした。クラウドでA100(80GB)を時間借りして、vLLMという定番の推論サーバーに載せるだけ——のはずでした。vLLMは高速な推論で広く使われていて、公式の手順も用意されています。これは楽勝だろう、と。
ところが、ここからが長かったのです。
最初に当たったGPUは、入っているドライバが古く、vLLMがうまく起動してくれませんでした。クラウドGPUはホストごとにドライバのバージョンがまちまちで、どうやら相性の悪いホストを引いてしまったようです。そこで「次は、ドライバが新しいかどうかを先に確かめる」と決め、CUDA 12.8以降を指定してPodを取り直しました。新しく確保したA100は、ドライバ575.57.08。ここでようやく、土台が整いました。
ところが、それでも一筋縄ではいきませんでした。DiffusionGemmaは公開されたばかりで、vLLMの最新版がまだこの新しいモデルに安定して噛み合ってくれません。最終的に、vLLM経由はいったん諦めました。代わりに、Transformersから直接モデルを呼び出す素朴なやり方に切り替えたところ、ようやく素直に動いてくれました。遠回りはしましたが、出力の形式は他の3エンジンと完全に同じに揃えてあるので、このあとの採点(CER比較)の公平性は保たれています。
(余談ですが、最初はAWSで動かすつもりでした。ただ、GPUの利用上限を引き上げる申請が審査待ちで間に合わず、すぐに借りられたRunPodへ切り替えました。この「とにかく動かせる環境を探す」感じも、新しいモデルならではかもしれません。)
かかった費用は、環境構築の試行錯誤も込みで、合計およそ420円。時間は数時間でした。お金の面では拍子抜けするほど安かったのですが、本当のコストはお金ではなく、「動かすまでの時間」の方にありました。
……ここまで読んで、おや、と思われた方もいるかもしれません。DiffusionGemmaの売りは「生成の速さ」のはず。その速いはずのモデルを、動かすまでにこれだけ手間取った。この皮肉については、最後にもう一度ふれます。
検証の設計
検証のやり方は、これまでと同じものを使い回しています。シリーズを続けてきた強みは、ここにあります。
読ませる画像は、おなじみの4枚です。
① 縦書き —— 縦組みの短い文章
② 請求書 —— 表組みを含む定型文書
③ 多段組み —— 左右2段に分かれたレイアウト
④ 低解像度 —— わざと解像度を落とした、にじんだ画像
公平を期すため、4つのエンジンにはまったく同じ画像を、一字一句同じプロンプトで渡しています。各画像は独立したリクエストで処理し、前の結果を引きずらないようにしました。DiffusionGemmaだけは、前章のとおり自前のGPU(A100 80GB)で動かしています。
採点には**CER(文字誤り率, Character Error Rate)**を使います。正解のテキストと出力を比べて、何文字ぶん間違えたかの割合を出すもので、低いほど高精度です。比較がブレないよう、表記ゆれの影響を抑える前処理(空白の除去、表の記号の除去、全角・半角をそろえるNFKC正規化)をかけたうえで、全エンジンを同じ物差しで採点しています。
なお、採点にはひとつだけ注意点があるのですが、それは結果のところで正直にお話しします。
DiffusionGemmaに、4枚を食わせてみる
環境さえ整えば、あとはこれまでと同じです。縦書き・請求書・多段組み・低解像度——おなじみの4枚を、他の3エンジンと一字一句同じプロンプトで読ませていきます。1枚ずつ、順番に見ていきましょう。
① 縦書き —— いきなり good な滑り出しでした。文字誤り率(CER)は0.8%。ほんのわずかな取りこぼしだけで、ほぼ完璧に読めています。縦組みの日本語をここまで素直に処理できるのは、正直なところ意外でした。新方式とはいえ、文字を「読む」基礎体力はしっかりある、という第一印象です。
② 請求書 —— こちらは数字の上では47%前後と、少し悪く見えます。ただ、これは文字そのものを読み間違えているというより、「どの順番で項目を拾うか」という読み順のズレが主な原因です(この点は全エンジンに共通して効いているので、あとでまとめて説明します)。文字認識そのものは、ここでも安定していました。
③ 多段組み —— ここで、つまずきます。CERは75%。出力を見ると、左右の段を行ったり来たりしながら、文章が混ざってしまっていました。……この崩れ方、どこかで見た覚えがあります。そう、前回Geminiが、そしてその前にYomiTokuが見せたのと、ほとんど同じ"混線"でした。読む方式が新しくなっても、複数段のレイアウトを正しく追う、という壁は越えられなかったようです。
④ 低解像度 —— わざと解像度を落としたこの1枚は、50.4%。さすがに楽な相手ではありませんでしたが、ここで小さな見どころがありました。実は同じ画像で、Geminiは57.2%。つまりこの低解像度に関しては、新顔のDiffusionGemmaの方が、評判のGeminiよりわずかに上だったのです。
さて、1枚ずつの感触はつかめました。では、4つのエンジンを横に並べると、どう見えてくるのでしょうか。
4つを、並べてみる
ここで、4つのエンジンのスコアを一枚の表にまとめてみます。数字は文字誤り率(CER)で、低いほど高精度です。
エンジン | ①縦書き | ②請求書 | ③多段組み | ④低解像度 | 平均 |
|---|---|---|---|---|---|
Claude | 0.0% | 47.0% | 0.0% | 34.8% | 20.5% 🥇 |
DiffusionGemma | 0.8% | 47.3% | 75.0% | 50.4% | 43.4% |
Gemini | 0.0% | 47.0% | 75.0% | 57.2% | 44.8% |
YomiToku | 18.0% | 67.4% | 79.9% | 69.3% | 58.7% |
平均で見ると、Claudeが20.5%で頭ひとつ抜けています。続いてDiffusionGemmaが43.4%、Geminiが44.8%、YomiTokuが58.7%という並びになりました。新顔のDiffusionGemmaが、評判のGeminiをわずかに上回って2位につけた、というのは少し意外な結果です。
ただ、平均だけを見ていても、この検証のおもしろいところは見えてきません。画像ごとに分けて、棒グラフにしてみます。
こうして並べると、3つのことが浮かび上がってきます。
ひとつ目。 ①縦書きでは、Claude・Gemini・DiffusionGemmaの3つが、ほぼ0%でした。「文字を読む」だけなら、新顔も含めてVLM勢はどれも優秀で、差はほとんどありません。YomiTokuだけが18%と少し離されていますが、これも実用上は読める範囲です。
ふたつ目、そして最大の山場。 ③多段組みです。ここでは、Claudeだけが0%。残りの3つ——YomiToku・Gemini・DiffusionGemmaは、そろって75〜80%まで跳ね上がりました。先ほど見たとおり、左右の段が交ざる「混線」を起こしています。読む方式が拡散方式になっても、この壁は越えられませんでした。「文字を読む力」はみな高いのに、「レイアウトを理解する力」になると、依然としてClaudeだけが別格——前回からの主題が、4つ目のエンジンを加えても、そのまま当てはまったのです。
みっつ目。 ④低解像度では、Claudeが34.8%でやはり最も強く、その次にDiffusionGemma(50.4%)、Gemini(57.2%)と続きました。ぼやけた画像では、新顔のDiffusionGemmaが評判のGeminiを上回る場面もあった、という点は小さな見どころです。
②請求書の「47%」について(正直なところ)
ひとつ、表を見て「あれ?」と思われた方への補足です。②請求書だけ、ほぼ全員が47%前後で並んでいます。これは、4つのエンジンがそろって同じ誤読をした……わけではありません。
実際、②の出力(先ほどの画像)を見ると、社名も住所も金額も、文字はすべて正しく読めています。それでもCERが47%になるのは、項目を拾っていく「読み順」が、採点用の正解データと違っているためです。表組みの請求書では、人間でも「どの順で読むか」は割れます。
この差は全エンジンに等しく効いているので、順位の比較には影響しません。ただ、②の絶対値だけは「読み違いの多さ」ではなく「読み順のクセ」を表している——その点だけは、正直に断っておきます。
分かったこと
4つのエンジンを同じ土俵に並べてみて、見えてきたことを整理します。
1つ目。王者Claudeの強さは、4人目を加えても揺らがなかった。
平均20.5%という数字もさることながら、効いているのは③多段組みでただ一つ0%を出したことです。文字をどれだけ正確に読めるか——その点では、今やGemini・Claude・DiffusionGemmaの差はほとんどありません。「文字を読む」だけなら、VLMはどれを選んでもだいたい優秀、という時代になりました。差がつくのは、その先。「複数の段や複雑なレイアウトを、正しい順序で理解できるか」です。そして今のところ、そこで頭ひとつ抜けているのがClaude、という構図は今回も変わりませんでした。
2つ目。新顔のDiffusionGemmaは、なかなかの健闘だった。
平均ではGeminiをわずかに上回り、専用OCRのYomiTokuには明確に勝ちました。低解像度の画像では、評判のGeminiより上に出る場面もありました。拡散方式という新しい作り方でも、文字認識の地力は、既存のVLMにきちんと並んでいます。一方で、③多段組みではGeminiやYomiTokuと同じく混線しました。つまり、「新方式だからレイアウトも解ける」わけではない。文字を読む力と、レイアウトを理解する力は、生成の方式とは別の軸にある——今回いちばんの収穫は、この見立てが補強されたことかもしれません。
3つ目。"速さがウリ"のはずが、いまは「動かすまで」が最大のコストだった。
ここが、冒頭で予告した皮肉です。DiffusionGemmaの売りは生成の速さでした。ところが実務で触ってみると、その速さを味わう以前に、環境を整えて起動させるところでいちばん時間を使いました。出たばかりのモデルは、それを動かす周辺のソフトウェアがまだ追いついていない。これは性能の問題ではなく、エコシステムの成熟度の問題です。裏を返せば、APIキー1本ですぐ呼べて、しかも精度も高いホスト型サービス(今回でいうClaude)の「すぐ使える」という価値が、あらためて際立った検証でもありました。
実務的な落としどころをまとめると、こうなります。単段の定型文書をただ読むだけなら、もう専用OCRでもクラウドVLMでも大差ありません。選ぶ基準は「複雑なレイアウトを理解できるか」と「どれだけ手間なくすぐ使えるか」。前者を重く見るならClaude、コスト重視で単純な文書が中心ならGeminiクラスでも十分。そして拡散方式の新顔は、地力は本物ながら、本格的に使うのはもう少し環境が枯れてから——というのが、いまの正直な見立てです。
おわりに
これで、日本語OCRの検証は4回目になりました。1回目はYomiTokuの単体検証、2回目がYomiToku対Claude、3回目がClaude対Gemini、そして今回、新方式のDiffusionGemmaを加えて4つを横並びにしました。同じ4枚の画像と同じ採点を毎回使い回せたおかげで、エンジンが増えてもブレずに比べることができたと思います。
結論として、印字された文書をきれいに読むだけなら、選択肢はもうたくさんあります。本当の差は、レイアウトの理解と、導入のしやすさに出る。新しい拡散方式のモデルも、その地力は確かなものでした。あとは、それを誰もが気軽に動かせるようになる日を待ちたいところです。
さて、ここまでの4枚は、すべて「印字された」文書でした。次にやってみたいのは、もっと手強い相手——手書きです。崩れた手書き文字を相手にしたとき、専用OCRとVLM、そして拡散方式の新顔は、どこまで読めるのか。続きは、また手を動かしてみます。
