
前回までのあらすじ
前回の記事では、Sakana AIのマルチエージェントAPI「Fugu Ultra」を、単体のClaude Opus 4.8とコーディング(バグ修正)で勝負させました。結果は、正答率・速度・コストのすべてで単体Opusに軍配。とくにコストは、表に見えないorchestrationトークン(裏で動く分)まで含めると約4.4倍にふくらむ、という発見がありました。
ただ、あのときのお題は「単体でも一発で解けるくらいの難しさ」でした。そこで今回は、「もっと難しくしたら?」「わざと引っかけたら?」と、お題を変えて2回戦・3回戦をやってみます。Fuguにもどこかで勝ってほしい、という下心もこめて。
検証のやり方は前回と同じです。同じお題をFugu UltraとOpus 4.8の両方に解かせ、仕様だけ渡して(答え合わせ用テストは見せない)、隠しテストで○×を判定。1問あたり3回ずつ試して、ばらつきも見ます。
第2弾:依存連鎖バグ ── 「1つ直すと別が壊れる」お題
前回が「単発のバグ」だったので、今回は逆に、直し方をまちがえると別の場所が壊れる、相互依存のあるバグを用意しました。
たとえば「口座台帳」のお題は、残高・明細・取消(rollback)が連動しています。取消の処理だけを素直に直すと、明細は戻るのに残高が戻らず、つじつまが合わなくなる ── そんな仕掛けです。ほかに「区間集合」(重なり判定・包含・総延長が連動)、「依存グラフ」(ビルド順序とサイクル検出が連動)の計3問。いずれも「全部のテストが同時に通って初めて正解」としました。
なお、これらのお題は事前に「素朴に1か所だけ直した実装はちゃんと失敗する」ことを確認しています。つまり、全体を見渡して直さないと解けない設計です。
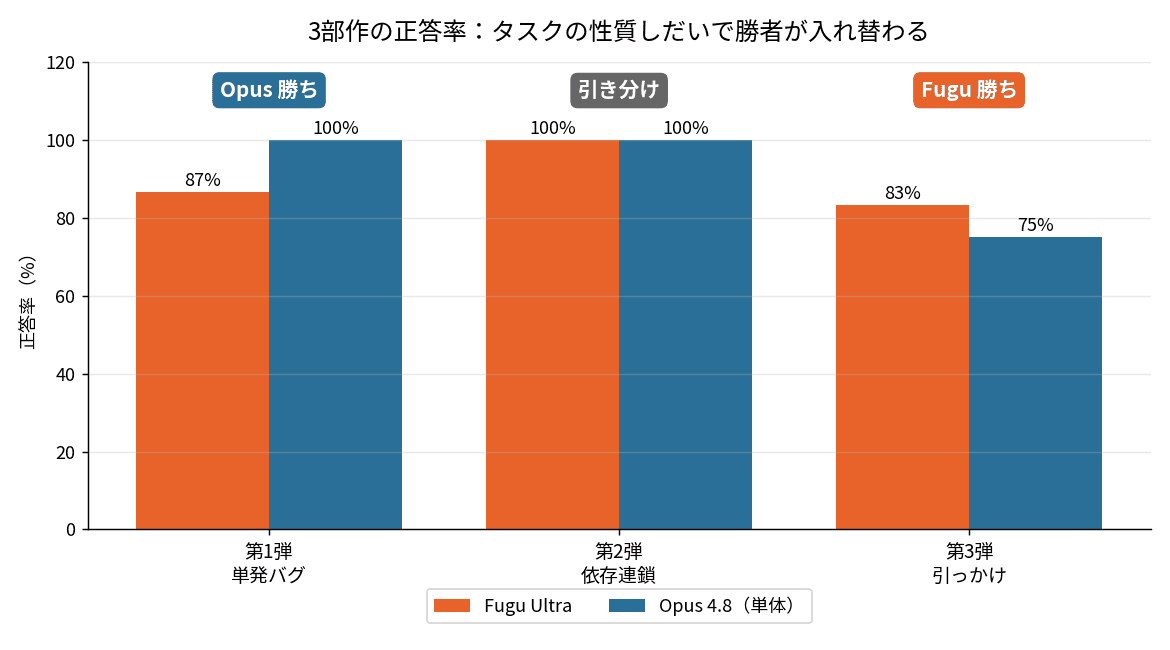
結果はこうなりました。
Fugu Ultra:9/9(100%)
Opus 4.8:9/9(100%)
まさかの全問正解で引き分け。 難しくしたつもりが、両方ともきっちり解いてきました。「全体を見渡す力」では差がつかなかった、というわけです。ただし速度はOpusが約8〜10倍速、コストはFuguが約3.3倍のまま。正答率で並んでも、このハンデは変わりませんでした。
第3弾:引っかけ問題 ── 「見直し」が効く土俵
2連敗(厳密には1敗1分)のFugu。ここで作戦を変えました。Fuguの強みは「一発の正確さ」ではなく「裏で複数モデルが見直し合うこと」のはず。だったら、一発で書くと引っかかるけれど、見直せば気づくエッジケースを仕込めば、Fuguにもチャンスがあるのでは ── そう考えて、引っかけ問題4問を用意しました。
ローマ数字:変換そのものは簡単。でも「
IIIIは不正(正しくはIV)」といった妥当性チェックが抜けやすい四捨五入:Pythonの
round()は「銀行家丸め」なので、round(0.5)は0。素直に使うと外すn等分:「サイズで割る」と、できる部分の数も均等さも狂う
バージョン比較:
'1.10'を文字列で比べると'1.2'より小さいと誤判定する
どれも「ついやってしまう素直な実装」が罠にハマるお題です。結果は ──
Fugu Ultra:10/12(83.3%) 🏆
Opus 4.8:9/12(75.0%)
ついに、正答率でFugu Ultraが単体Opusを上回りました。 3度目の正直です。
勝負を分けた「ローマ数字」
差がついたのは、4問のうち「ローマ数字」の1問だけでした。

ほかの3問(四捨五入・n等分・バージョン比較)は、両者とも3回とも正解。差が出たのはローマ数字で、内訳はこうです。
Fugu Ultra:3回中1回だけ正解(1/3)
Opus 4.8:3回とも不正解(0/3)
両者とも引っかかったのは、MMMM(4000)という入力でした。標準のローマ数字は3999までで、Mを4つ並べる表記は本来ありません。ところが、この「上限」のチェックは見落とされやすく、Opusは3回とも素通り。Fuguも2回は素通りしましたが、3回のうち1回だけ、内部のどこかで「これは不正では?」と気づいて正解にたどり着きました。
ちなみに白状すると、このお題を準備していた私自身も、最初に書いた検証用の正解コードでまったく同じ罠(3999の上限)を踏んでいました。人でもAIでも引っかかる、なかなか良い罠だったということです。
3本勝負を振り返って
3回の勝負を並べてみます。
検証 | お題 | 結果 |
|---|---|---|
第1弾 | 単発バグ修正 | Opus勝ち(13/15 vs 15/15) |
第2弾 | 依存連鎖バグ | 引き分け(9/9 vs 9/9) |
第3弾 | 引っかけ問題 | Fugu勝ち(10/12 vs 9/12) |
見てのとおり、お題の性質しだいで勝者が入れ替わりました。素直な実装力では単体Opusが強く、見直しが効く引っかけではFuguが上回る。「マルチエージェントは単体より強い/弱い」と一言で言える話ではなく、「どんなタスクか」によるわけです。
ただし、勝っても負けても変わらなかったものがあります。コストです。

3回を通して、Fuguの実コストは一貫してOpusの3〜4倍でした。裏のorchestrationトークンが毎回効いてくるためです。速度も、Fuguはおおむね10倍前後遅いまま。さらに第3弾では、ある1問でFuguが**約609秒(10分超)**かかるという外れ値も出ました(ほかは20〜60秒程度)。実行時間が読みにくいのも、マルチエージェントならではの特徴と言えそうです。
まとめ
3本勝負を通してわかったことを、ゆるくまとめます。
正答率では、お題の性質によって勝者が変わりました。単純な実装なら単体Opusが安定して強く、見直しが効く引っかけ問題ではFuguが上回る場面もある。一方で速度(約10倍遅い)とコスト(3〜4倍高い、裏トークン込み)のハンデは、勝っても負けても一貫して残りました。
Fugu Ultraのようなマルチエージェント型を採用するなら、「正答率が単体を上回るかどうか」だけでなく、「そのために何倍の時間とコストを払うのか」「実行時間が読めるか」まで含めて見たほうがよさそうです。今回の範囲では、MMMMの罠のように「単体が一発で見落としがちな細部」では強みが出ましたが、それ以外では単体の高性能モデルで十分なケースが多い、というのが正直な手応えでした。
次にやってみたい検証
今回はすべて「コーディング」というFuguの主戦場での勝負でした。次は、まだ試せていない切り口を掘ってみたいと考えています。
① Fuguで別領域(長文・リサーチ系) 今回のサブスクのまま追加コストなしで試せる範囲として、長い文章からの正確な情報抽出や、複数ソースをまたぐ調査タスクなど、「コーディング以外」でFuguの真価を見てみたいところです。コーディングでは見えなかった強み・弱みが出るかもしれません。
② Sakana Marlinの検証 Fuguと同時に公開された自律型リサーチエージェント「Marlin」も気になっています。ただしMarlinは法人向けで料金体系がFuguとは別(月額数万円〜の規模)のため、検証するには別途の準備が必要です。「最大8時間の自律リサーチ」という性質上、成果物の質をどう評価するか、という設計の工夫も求められます。ここは費用対効果を見ながら、改めて検討したいテーマです。
なお、もう1つのプロダクト「Sakana Chat」については、現状ではAPIが公開されておらず、今回のような自動化した定量検証が難しいため、試すとしても「使ってみた感想」レベルの紹介になりそうです。
検証環境:Fugu Ultra(fugu-ultra-20260615、Responses API、reasoning effort=high)、Claude Opus 4.8。各お題は3回ずつ試行。コストはFugu Ultra入力$5/出力$30(per 1Mトークン、272Kコンテキスト以下、orchestrationトークン込み)で計算。Opus 4.8のレートは暫定値のため、正確なコストは最新の公式レートで再計算してください。お題と判定基準は事前に妥当性を確認のうえ公開しています。
