無料の日本語OCR「YomiToku」は、Claudeとどこまで戦えるのか
無料の日本語OCR「YomiToku」は、Claudeとどこまで戦えるのか

はじめに以前、日本語特化のOCRエンジン「YomiToku」を実際に触ってみた記事を書きました。横書きだと段落の順番が逆さまになる、みたいな小さな癖も含めて、手を動かして確かめた記録です。
今回はその続きです。日本語の文書をOCRしたいとき、「結局どれを使えばいいの?」って、けっこう迷いますよね。そこで、YomiTokuを他のツールと比べてみることにしました。
ひとつだけ、先に書いておきたいことがあります。YomiTokuはGitHubで公開されているOSSで、無料で使えます(今回は v0.13.0 を使いました)。ただしライセンスは CC BY-NC-SA 4.0 で、商用で使うには別途ライセンスが必要です。いっぽう、今回の対戦相手に選んだのは、有料のマルチモーダルLLM「Claude」(Opus 4.8)。
なので、これは「無料でローカルに動くOCRエンジン」対「有料のAPIで動くLLM」という、そもそも土俵がちょっと違う勝負でもあります。そのへんを踏まえたうえで、無料のYomiTokuが日本語の難所でどこまで戦えるのか、実際にぶつけて確かめてみました。
[画像:前回のYomiToku記事へのリンク/YomiTokuの画面(ご用意ください・任意)]
検証の設計
難所サンプルは、ぜんぶ自作しました
テスト画像は、日本語OCRがつまずきやすい「難所」を4種類、すべて自分で作りました。
① 縦書き(小説風の文章)
② 表・帳票(ダミーの請求書)
③ 横書きの多段組み(2カラムの記事風)
④ 低解像度(②をかすれさせたもの)
なぜ自作にしたかというと、理由は2つあります。ひとつは、公開記事なので著作権をきれいにクリアしたかったから。もうひとつは、描いた文字列をそのまま「正解テキスト」として保存しておけば、採点の基準がぴったり一致するからです。



採点のものさしは2つ
採点には2つの指標を使いました。
ひとつは CER(文字誤り率)。正解と出力を比べて、何文字違うかを割合で出します。低いほど良い数字です。
もうひとつは 文字カバー率。こちらは順番を気にせず、「正解の文字を、どれだけ拾えているか」を見ます。
なぜ2つも用意したのかは、やってみると自然に分かってきます。
比べる前には、出力をプレーンテキストに揃えて、全角・半角や空白・改行を正規化しました。土俵を揃えないと、フェアな比較になりませんからね。
カンニングを防ぐ工夫
Claude側は、4枚すべてに同じプロンプトを使って、1枚ずつ独立したリクエストで投げました。難所ごとにプロンプトを変えたり、前の画像のことを覚えたまま次を読ませたり、ということが起きないようにするためです。
まず、YomiTokuに食わせてみる
YomiToku(v0.13.0)に、4枚を順番に通していきます。
① 縦書き
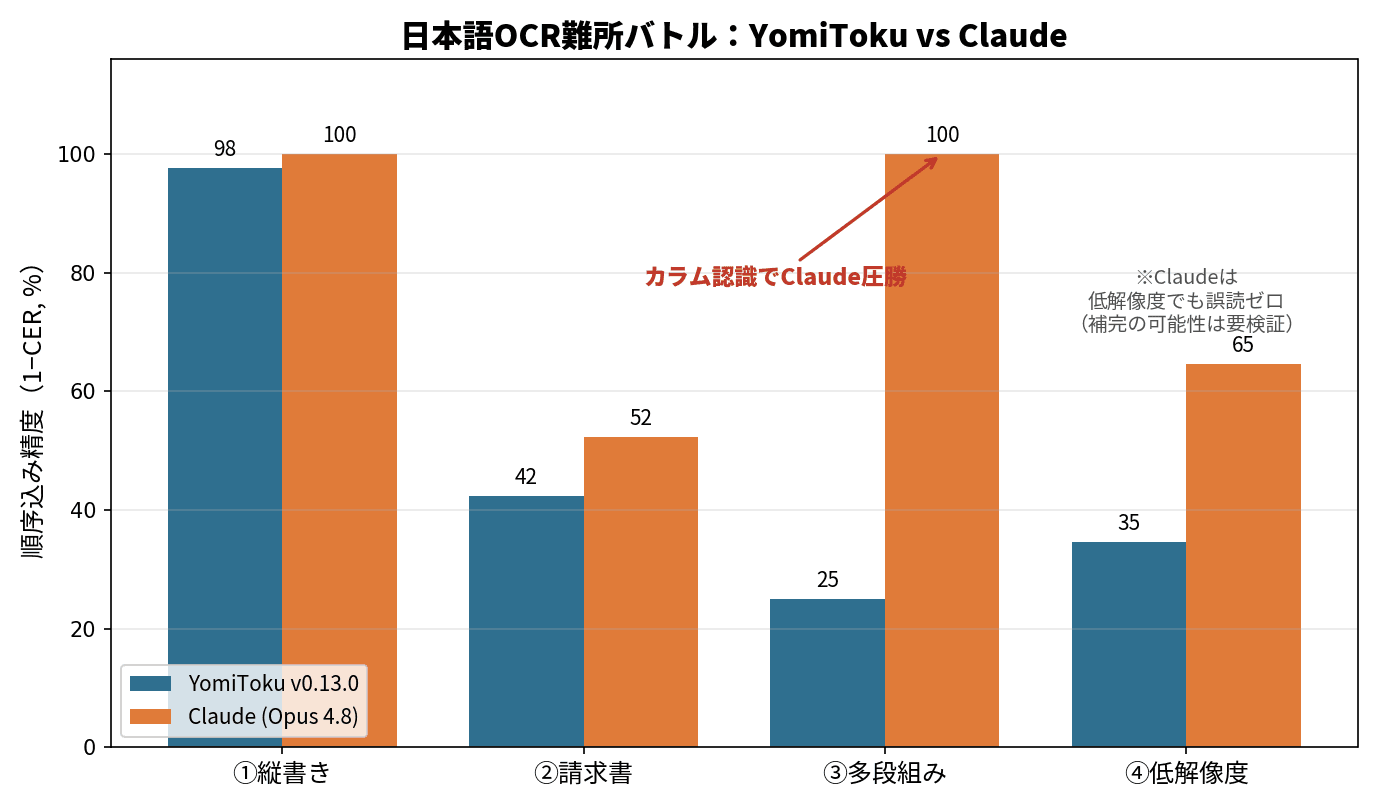
これはほぼ完璧でした。文章はちゃんと正しい順(右から左)で出てきて、間違いは読点「、」を数か所こぼした程度。CERは2.3%です。前回「横書きだと段落の順番が逆になる」と書きましたが、縦書きはむしろ素直に読める、という傾向がここでも一致しました。

② 表・請求書
ここはYomiTokuの得意分野でした。表は | 品目 | 数量 | 単価 | 金額 | という形でMarkdownのテーブルにきれいに変換され、金額も含めて誤読はゼロ。
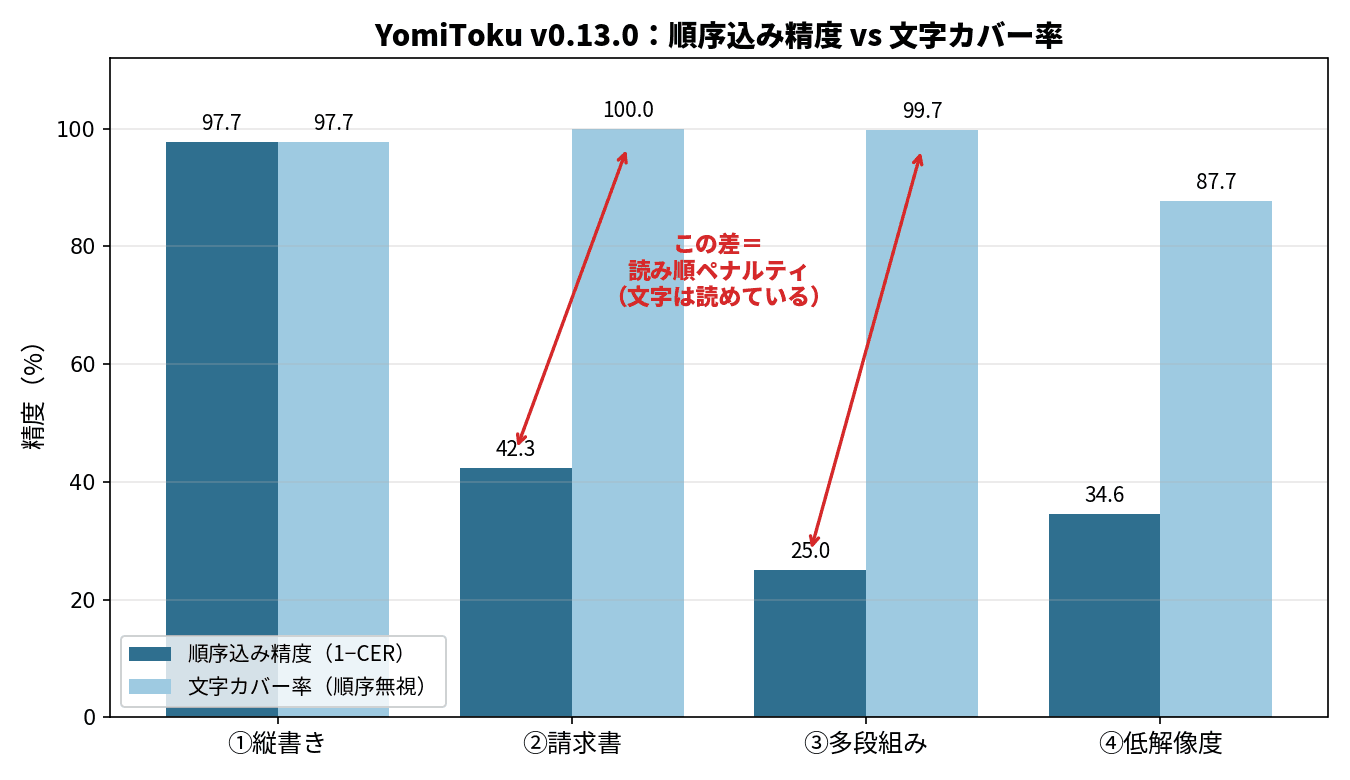
ところが、CERを計算すると57.7%という高い数字が出ます。でも、これは誤読のせいではありません。文字カバー率を見ると100%——つまり一文字も間違っていないんです。CERが高くなったのは、出力されたブロックの並び順が正解と違っていたから。
ここで、CERという指標の落とし穴が見えてきます。請求書みたいに複数のかたまりがあるレイアウト文書だと、文字が完璧でも、並び順が違うだけでCERは大きくなってしまう。CERだけ見ていたら、この請求書を「精度が低い」と勘違いしていたはずです。だから文字カバー率との合わせ技が要るわけですね。

③ 多段組み
ここでYomiTokuはつまずきました。2つのカラムをうまく認識できず、左カラムの1行目と右カラムの1行目をつなげて読んでしまう「行の混線」が起きたんです。文字自体はほぼ全部拾えている(カバー率99.7%)のに、読み順が崩れてCERは75%まで上がりました。
ちなみに今回はデフォルト設定での結果です。YomiTokuには読み順を指定するオプションもあるので、改善の余地はありそうです(このへんはまた別途試してみたいところ)。

④ 低解像度
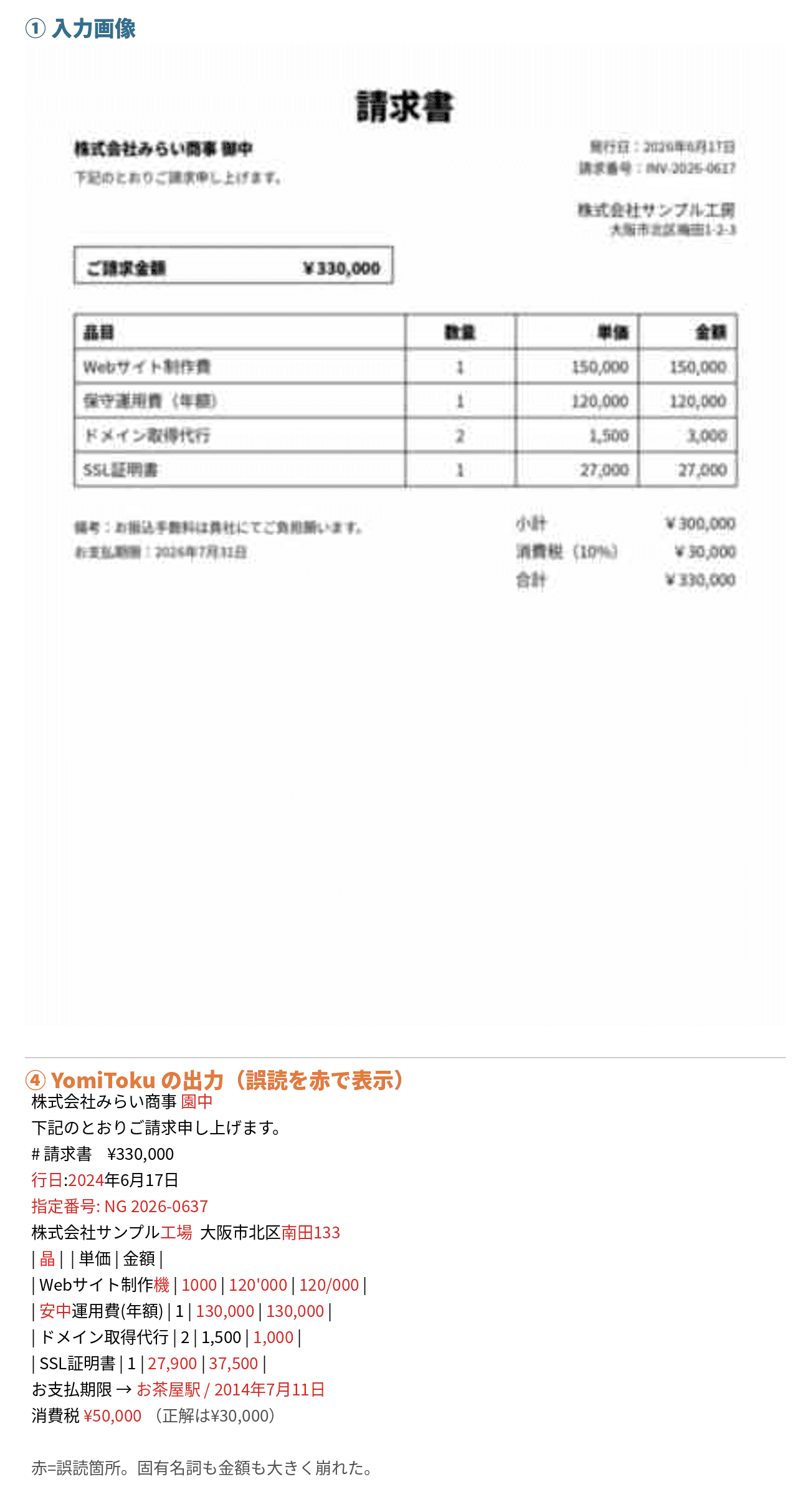
低解像度では、はっきり崩れました。カバー率も87.7%まで落ちて、固有名詞や金額がガタガタに。
「御中」→「園中」
「サンプル工房」→「サンプル工場」
「梅田1-2-3」→「南田133」
「請求番号:INV-2026-0617」→「指定番号: NG 2026-0637」
「お支払期限:2026年7月31日」→「お茶屋駅 2014年7月11日」
潰れた文字を、見えたなりに読み間違えています。最後のなんて、住所と勘違いしたんでしょうか。
次に、Claudeに食わせてみる
同じ4枚を、まっさらな状態のClaudeに1枚ずつ通します。
①〜③
縦書きは完璧(CER 0%)。請求書も誤読ゼロでMarkdownテーブルもきれいでしたが、CERはやっぱり順番の影響で残りました。そして多段組み——YomiTokuが混線したところを、Claudeは左カラムを最後まで読んでから右カラムへ移って、正しい順で出力してくれました。CERは0%。レイアウトの読み取りはLLMの得意分野なんだな、とここではっきり感じました。

④ 低解像度
そして低解像度。Claudeは、YomiTokuが崩れた箇所も含めて、誤読ゼロ(カバー率100%)で出力しました。
……ここで、ちょっと引っかかったんです。
低解像度って、人間が見ても潰れて読みにくい小さな文字がありますよね。それをClaudeが完璧に出してきたのは、本当に画像から読めているのか。それとも「これは請求書だから、たぶんこう書いてあるはず」って文脈から補っているのか。もし後者だとしたら、画像にない情報を勝手に作文していることになります。
ちょっと気になったので、確かめてみることにしました。

Claudeは本当に読んでいるのか——罠を仕掛ける
確かめるために、こんな実験を用意しました。
わざと「ありえない値」を仕込んだ請求書を作るんです。もしClaudeが文脈で補うタイプなら、これを「自然な値」に直してくるはず。逆に画像どおり読むなら、ありえない値をそのまま出すはず。そういう仕掛けです。
仕込んだ罠は、こんな感じ。
品目を「ぽんぽこ保守費」「月面ドメイン取得」「量子SSL証明書」に(ふざけてるようで、これが効くんです)
数量×単価と金額が合わない(例:3 × 88,888 なのに金額は 12,345)
請求番号をランダムな「INV-7XK9-2580」に
小計・消費税・合計の計算がまったく合わない(小計123,456+税55,555 ≠ 合計199,011)
これを 高解像度版 と 低解像度版 の両方で用意しました。高解像度で正しく読めて、低解像度で値が変わるなら、「低解像度だから補完した」と言える——そういう対照実験です。
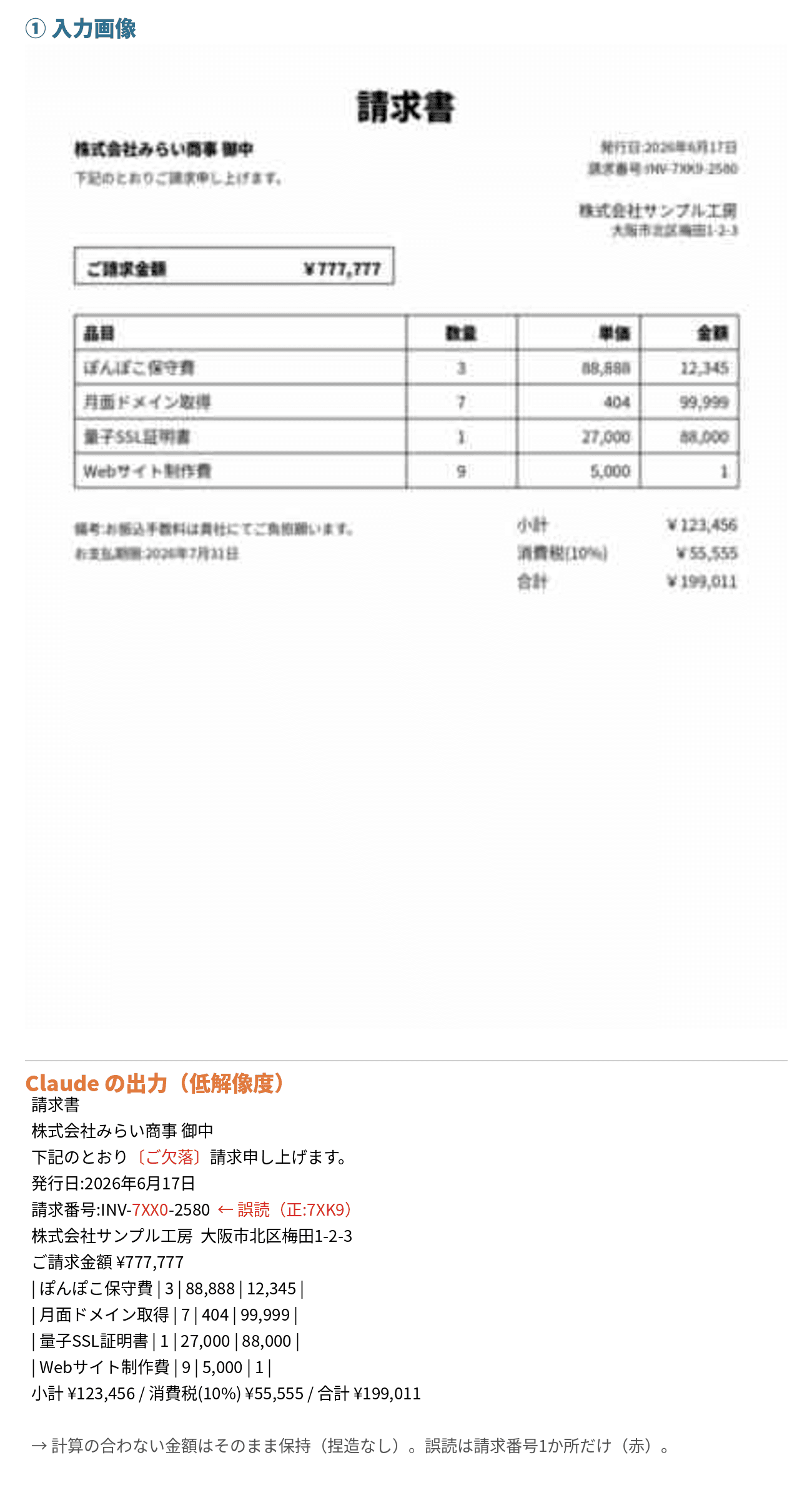
結果は……
高解像度版では、Claudeは仕込んだ異常値を全部そのまま出力しました。計算の合わない金額も、ランダムな請求番号も、画像どおりに。
低解像度版でも、金額はすべてそのまま。計算が合わない小計・消費税・合計を「直す」ことはしませんでした。変わったのは2か所だけ——ランダムな請求番号「INV-7XK9-2580」が「INV-7XX0-2580」に化けて、本文の「ご」が1文字抜けただけです。
分かったこと
ここまでの結果を整理します。
まず、最初に疑った「Claudeは低解像度で値を補完(捏造)しているのでは?」は、外れました。計算がまったく合わない金額を、Claudeは一切直さずそのまま出したんです。画像に書いてある内容には、ちゃんと忠実でした。
じゃあ低解像度での間違いは何だったのか。それは「捏造」ではなく、ただの「誤読」でした。ランダムな請求番号の小さい文字を読み間違えただけで、見えないものを作り出したわけではありません。
ただ、もう一歩踏み込むと、別のことも見えてきます。最初の標準的な請求書(④低解像度)では、Claudeは誤読ゼロでした。あのときの請求番号「INV-2026-0617」は、発行日「2026年6月17日」と一致する、予測できるパターンだったんですね。だから低解像度でも正しく読めた。いっぽう今回のランダムな「INV-7XK9-2580」は文脈の助けがなくて、誤読した。
つまり——Claudeは値を捏造はしないけれど、文脈に助けられている。予測できる内容なら誤読を防げるけど、予測できない値は低解像度で間違える、ということです。
そして、これがYomiTokuとの本質的な違いにつながります。
YomiToku は、画像のピクセルだけを読みます。文脈の助けはありません。だから低解像度では素直に崩れますが、崩れ方が「お茶屋駅」みたいに明らかに変で、人間が気づきやすい。
Claude は、画像と文脈の両方で読みます。値を捏造はしませんが、文脈補正が効くぶん、予測できる文書に強い。ただし間違えたときの結果が「INV-7XX0-2580」みたいに自然な見た目で、人間が見逃しやすい。
ここ、地味だけど大事なポイントだと思います。
結局、どう使い分ければいいのか
今回の検証から見えた、用途別の選び方をまとめてみます。
YomiTokuが向いている場面
無料・ローカル・オフラインで動かしたい
機密文書を外部に出したくない
画像への忠実さが大事で、間違ったときに分かりやすく崩れてほしい
(ただし商用利用には別途ライセンスが必要)
Claudeが向いている場面
定型の、予測できる文書を、多少の欠けごと賢く読んでほしい
多段組みみたいな複雑なレイアウトの読み順を正しく取りたい
(ただしランダムな値や低品質な画像では、自然な見た目で間違えることがあるので、検品はしたほうが安心)
精度の数字だけ見れば、Claudeが上回る場面が多かったです。でも「無料か有料か」「画像に忠実か、文脈で補うか」という軸で見ると、どっちが優れているという話ではなくて、用途で選ぶものだなあ、というのが今回たどり着いた結論でした。
で、結局どっちが勝ったのか
ここはハッキリ書いておきます。精度(CER)の総合成績では、Claudeの勝ちでした。 平均CERはClaudeが20.8%、YomiTokuが50.1%。4つの難所すべてでClaudeが上回りました。
ただ、これは「YomiTokuがダメ」という話ではありません。無料でローカルに動いて、画像に忠実で、間違ったときも分かりやすく崩れる——この特性が効く場面は確実にあります。むしろ、無料のOSSが有料のLLMをここまで追い込んだ、と言うべきかもしれません。
用途で選ぶのが大前提。そのうえで、「日本語OCRの精度でどっちが上か」という今回の土俵に限れば、軍配はClaudeに上がりました。
次回:勝者Claude vs Gemini
というわけで、今回勝ち上がったのは Claude です。
でも、日本語OCRで評判のいいマルチモーダルLLMは、もうひとつあります——Gemini です。次回は、この勝者Claudeを、Geminiにぶつけます。同じ難所セット・同じ採点で、Claude vs Gemini の頂上決戦。
果たしてClaudeは連勝できるのか、それともGeminiが上をいくのか。お楽しみに。
はじめに以前、日本語特化のOCRエンジン「YomiToku」を実際に触ってみた記事を書きました。横書きだと段落の順番が逆さまになる、みたいな小さな癖も含めて、手を動かして確かめた記録です。
今回はその続きです。日本語の文書をOCRしたいとき、「結局どれを使えばいいの?」って、けっこう迷いますよね。そこで、YomiTokuを他のツールと比べてみることにしました。
ひとつだけ、先に書いておきたいことがあります。YomiTokuはGitHubで公開されているOSSで、無料で使えます(今回は v0.13.0 を使いました)。ただしライセンスは CC BY-NC-SA 4.0 で、商用で使うには別途ライセンスが必要です。いっぽう、今回の対戦相手に選んだのは、有料のマルチモーダルLLM「Claude」(Opus 4.8)。
なので、これは「無料でローカルに動くOCRエンジン」対「有料のAPIで動くLLM」という、そもそも土俵がちょっと違う勝負でもあります。そのへんを踏まえたうえで、無料のYomiTokuが日本語の難所でどこまで戦えるのか、実際にぶつけて確かめてみました。
[画像:前回のYomiToku記事へのリンク/YomiTokuの画面(ご用意ください・任意)]
検証の設計
難所サンプルは、ぜんぶ自作しました
テスト画像は、日本語OCRがつまずきやすい「難所」を4種類、すべて自分で作りました。
① 縦書き(小説風の文章)
② 表・帳票(ダミーの請求書)
③ 横書きの多段組み(2カラムの記事風)
④ 低解像度(②をかすれさせたもの)
なぜ自作にしたかというと、理由は2つあります。ひとつは、公開記事なので著作権をきれいにクリアしたかったから。もうひとつは、描いた文字列をそのまま「正解テキスト」として保存しておけば、採点の基準がぴったり一致するからです。
採点のものさしは2つ
採点には2つの指標を使いました。
ひとつは CER(文字誤り率)。正解と出力を比べて、何文字違うかを割合で出します。低いほど良い数字です。
もうひとつは 文字カバー率。こちらは順番を気にせず、「正解の文字を、どれだけ拾えているか」を見ます。
なぜ2つも用意したのかは、やってみると自然に分かってきます。
比べる前には、出力をプレーンテキストに揃えて、全角・半角や空白・改行を正規化しました。土俵を揃えないと、フェアな比較になりませんからね。
カンニングを防ぐ工夫
Claude側は、4枚すべてに同じプロンプトを使って、1枚ずつ独立したリクエストで投げました。難所ごとにプロンプトを変えたり、前の画像のことを覚えたまま次を読ませたり、ということが起きないようにするためです。
まず、YomiTokuに食わせてみる
YomiToku(v0.13.0)に、4枚を順番に通していきます。
① 縦書き
これはほぼ完璧でした。文章はちゃんと正しい順(右から左)で出てきて、間違いは読点「、」を数か所こぼした程度。CERは2.3%です。前回「横書きだと段落の順番が逆になる」と書きましたが、縦書きはむしろ素直に読める、という傾向がここでも一致しました。
② 表・請求書
ここはYomiTokuの得意分野でした。表は | 品目 | 数量 | 単価 | 金額 | という形でMarkdownのテーブルにきれいに変換され、金額も含めて誤読はゼロ。
ところが、CERを計算すると57.7%という高い数字が出ます。でも、これは誤読のせいではありません。文字カバー率を見ると100%——つまり一文字も間違っていないんです。CERが高くなったのは、出力されたブロックの並び順が正解と違っていたから。
ここで、CERという指標の落とし穴が見えてきます。請求書みたいに複数のかたまりがあるレイアウト文書だと、文字が完璧でも、並び順が違うだけでCERは大きくなってしまう。CERだけ見ていたら、この請求書を「精度が低い」と勘違いしていたはずです。だから文字カバー率との合わせ技が要るわけですね。
③ 多段組み
ここでYomiTokuはつまずきました。2つのカラムをうまく認識できず、左カラムの1行目と右カラムの1行目をつなげて読んでしまう「行の混線」が起きたんです。文字自体はほぼ全部拾えている(カバー率99.7%)のに、読み順が崩れてCERは75%まで上がりました。
ちなみに今回はデフォルト設定での結果です。YomiTokuには読み順を指定するオプションもあるので、改善の余地はありそうです(このへんはまた別途試してみたいところ)。
④ 低解像度
低解像度では、はっきり崩れました。カバー率も87.7%まで落ちて、固有名詞や金額がガタガタに。
「御中」→「園中」
「サンプル工房」→「サンプル工場」
「梅田1-2-3」→「南田133」
「請求番号:INV-2026-0617」→「指定番号: NG 2026-0637」
「お支払期限:2026年7月31日」→「お茶屋駅 2014年7月11日」
潰れた文字を、見えたなりに読み間違えています。最後のなんて、住所と勘違いしたんでしょうか。
次に、Claudeに食わせてみる
同じ4枚を、まっさらな状態のClaudeに1枚ずつ通します。
①〜③
縦書きは完璧(CER 0%)。請求書も誤読ゼロでMarkdownテーブルもきれいでしたが、CERはやっぱり順番の影響で残りました。そして多段組み——YomiTokuが混線したところを、Claudeは左カラムを最後まで読んでから右カラムへ移って、正しい順で出力してくれました。CERは0%。レイアウトの読み取りはLLMの得意分野なんだな、とここではっきり感じました。
④ 低解像度
そして低解像度。Claudeは、YomiTokuが崩れた箇所も含めて、誤読ゼロ(カバー率100%)で出力しました。
……ここで、ちょっと引っかかったんです。
低解像度って、人間が見ても潰れて読みにくい小さな文字がありますよね。それをClaudeが完璧に出してきたのは、本当に画像から読めているのか。それとも「これは請求書だから、たぶんこう書いてあるはず」って文脈から補っているのか。もし後者だとしたら、画像にない情報を勝手に作文していることになります。
ちょっと気になったので、確かめてみることにしました。
Claudeは本当に読んでいるのか——罠を仕掛ける
確かめるために、こんな実験を用意しました。
わざと「ありえない値」を仕込んだ請求書を作るんです。もしClaudeが文脈で補うタイプなら、これを「自然な値」に直してくるはず。逆に画像どおり読むなら、ありえない値をそのまま出すはず。そういう仕掛けです。
仕込んだ罠は、こんな感じ。
品目を「ぽんぽこ保守費」「月面ドメイン取得」「量子SSL証明書」に(ふざけてるようで、これが効くんです)
数量×単価と金額が合わない(例:3 × 88,888 なのに金額は 12,345)
請求番号をランダムな「INV-7XK9-2580」に
小計・消費税・合計の計算がまったく合わない(小計123,456+税55,555 ≠ 合計199,011)
これを 高解像度版 と 低解像度版 の両方で用意しました。高解像度で正しく読めて、低解像度で値が変わるなら、「低解像度だから補完した」と言える——そういう対照実験です。
結果は……
高解像度版では、Claudeは仕込んだ異常値を全部そのまま出力しました。計算の合わない金額も、ランダムな請求番号も、画像どおりに。
低解像度版でも、金額はすべてそのまま。計算が合わない小計・消費税・合計を「直す」ことはしませんでした。変わったのは2か所だけ——ランダムな請求番号「INV-7XK9-2580」が「INV-7XX0-2580」に化けて、本文の「ご」が1文字抜けただけです。
分かったこと
ここまでの結果を整理します。
まず、最初に疑った「Claudeは低解像度で値を補完(捏造)しているのでは?」は、外れました。計算がまったく合わない金額を、Claudeは一切直さずそのまま出したんです。画像に書いてある内容には、ちゃんと忠実でした。
じゃあ低解像度での間違いは何だったのか。それは「捏造」ではなく、ただの「誤読」でした。ランダムな請求番号の小さい文字を読み間違えただけで、見えないものを作り出したわけではありません。
ただ、もう一歩踏み込むと、別のことも見えてきます。最初の標準的な請求書(④低解像度)では、Claudeは誤読ゼロでした。あのときの請求番号「INV-2026-0617」は、発行日「2026年6月17日」と一致する、予測できるパターンだったんですね。だから低解像度でも正しく読めた。いっぽう今回のランダムな「INV-7XK9-2580」は文脈の助けがなくて、誤読した。
つまり——Claudeは値を捏造はしないけれど、文脈に助けられている。予測できる内容なら誤読を防げるけど、予測できない値は低解像度で間違える、ということです。
そして、これがYomiTokuとの本質的な違いにつながります。
YomiToku は、画像のピクセルだけを読みます。文脈の助けはありません。だから低解像度では素直に崩れますが、崩れ方が「お茶屋駅」みたいに明らかに変で、人間が気づきやすい。
Claude は、画像と文脈の両方で読みます。値を捏造はしませんが、文脈補正が効くぶん、予測できる文書に強い。ただし間違えたときの結果が「INV-7XX0-2580」みたいに自然な見た目で、人間が見逃しやすい。
ここ、地味だけど大事なポイントだと思います。
結局、どう使い分ければいいのか
今回の検証から見えた、用途別の選び方をまとめてみます。
YomiTokuが向いている場面
無料・ローカル・オフラインで動かしたい
機密文書を外部に出したくない
画像への忠実さが大事で、間違ったときに分かりやすく崩れてほしい
(ただし商用利用には別途ライセンスが必要)
Claudeが向いている場面
定型の、予測できる文書を、多少の欠けごと賢く読んでほしい
多段組みみたいな複雑なレイアウトの読み順を正しく取りたい
(ただしランダムな値や低品質な画像では、自然な見た目で間違えることがあるので、検品はしたほうが安心)
精度の数字だけ見れば、Claudeが上回る場面が多かったです。でも「無料か有料か」「画像に忠実か、文脈で補うか」という軸で見ると、どっちが優れているという話ではなくて、用途で選ぶものだなあ、というのが今回たどり着いた結論でした。
で、結局どっちが勝ったのか
ここはハッキリ書いておきます。精度(CER)の総合成績では、Claudeの勝ちでした。 平均CERはClaudeが20.8%、YomiTokuが50.1%。4つの難所すべてでClaudeが上回りました。
ただ、これは「YomiTokuがダメ」という話ではありません。無料でローカルに動いて、画像に忠実で、間違ったときも分かりやすく崩れる——この特性が効く場面は確実にあります。むしろ、無料のOSSが有料のLLMをここまで追い込んだ、と言うべきかもしれません。
用途で選ぶのが大前提。そのうえで、「日本語OCRの精度でどっちが上か」という今回の土俵に限れば、軍配はClaudeに上がりました。
次回:勝者Claude vs Gemini
というわけで、今回勝ち上がったのは Claude です。
でも、日本語OCRで評判のいいマルチモーダルLLMは、もうひとつあります——Gemini です。次回は、この勝者Claudeを、Geminiにぶつけます。同じ難所セット・同じ採点で、Claude vs Gemini の頂上決戦。
果たしてClaudeは連勝できるのか、それともGeminiが上をいくのか。お楽しみに。
