日本語OCR「YomiToku」を触ってみた:書き方向で結果が変わる話
日本語OCR「YomiToku」を触ってみた:書き方向で結果が変わる話

日本語OCR「YomiToku」を触ってみた:書き方向で結果が変わる話
はじめに
日本語に特化したAI-OCRエンジン「YomiToku」をご存じでしょうか。GitHubで公開されているOSSで、日本語の文書画像解析に特化した国産のドキュメントAIです。
今回、実務で使えそうか検証するためにMacに環境を構築し、いろんな画像でOCRを試してみました。色々触ってみた結果、ちょっと意外な発見があったので、失敗も含めてまとめておきます。
YomiTokuとは
日本語特化のAI文書画像解析エンジン(Document AI)です。画像からの全文OCRに加えて、レイアウト解析・表構造認識まで一貫して行ってくれます。
主な特徴
日本語データセットで独自学習された4つのAIモデルを搭載
文字位置の検知(TextDetector)
文字列認識(TextRecognizer)
レイアウト解析(LayoutParser)
表構造認識(TableStructureRecognizer)
7000字を超える日本語文字に対応、縦書き・手書きもサポート
英語の文書にも対応
出力形式はHTML/Markdown/JSON/CSV/サーチャブルPDF
VRAM 8GB以内で動作、軽量モデルならCPUでも実用的
※ 公式ドキュメントでは、看板など紙以外にプリントされた文字の読み取り(情景OCR)は最適化対象外と明記されています。
⚠️ ライセンスに注意
OSS版は CC BY-NC-SA 4.0 ライセンスです。非商用(個人・学術・研究)は自由ですが、商用利用には別途ライセンス契約が必要です。クライアント案件や業務での本番利用を検討する場合は、開発元のmlism社またはAWS Marketplace版(YomiToku-Pro)を検討してください。
本記事は技術検証目的の非商用利用として実施しています。
環境構築(macOS)
前提
Python 3.10以上(今回は 3.13.1)
macOS(Apple Silicon / Intel どちらでもOK)
手順
# 作業フォルダ作成 mkdir ~/yomitoku-test cd ~/yomitoku-test # 仮想環境作成&有効化 python3 -m venv .venv source .venv/bin/activate # YomiTokuインストール
依存パッケージとしてPyTorch・ONNX Runtime・Transformers・OpenCV・pdf2imageなどが自動で入ります。合計数百MBなので少し時間がかかります。
基本の実行コマンド
yomitoku input.jpg -f md -v -o
-f md:Markdown形式で出力-v:可視化画像を出力-o results:出力先フォルダ指定
初回実行時はHugging Face Hubから4種類のモデルファイル(合計約650MB)が自動ダウンロードされます。
出力されるファイルの見方
yomitoku input.jpg -f md -v -o results を実行すると、resultsディレクトリに以下のファイルが生成されます。
ファイル | 中身 |
|---|---|
| 入力画像のコピー(何も加工されていない元画像) |
| レイアウト解析の可視化画像 |
| OCR結果の可視化画像 |
| 読み取ったテキスト(Markdown形式) |
可視化画像の凡例(公式より)
赤枠:図、画像等の位置
緑枠:表領域全体の位置
ピンク枠:表のセル構造
青枠:段落、テキストグループ領域
赤矢印:読み順推定の結果
今回遭遇した現象:可視化画像が横向きになる
今回の検証では、入力画像は縦向きなのに、出力される可視化画像(layout.jpg / ocr.jpg)だけが横向きになる現象が発生しました。入力画像のコピー(_xxx_p1.jpg)とMarkdown出力は正しい向きのままなので、認識結果自体には影響しませんが、可視化画像を確認する際は頭の中で90度回転させて見る必要がありました。
以降の検証で可視化画像を貼っている箇所は、この現象が起きた状態のままで掲載しています。
検証①:文字のない画像を入れてみる
見せ場:「文字なし画像でもエラーで落ちない」
まず、文字がまったく写っていないラーメンの写真で挙動を確認しました。実運用では「文字がない画像が誤って混ざっていた」というケースもあり得るので、エラー耐性を見る意味で重要なテストです。

結果
処理 | 時間 |
|---|---|
LayoutParser | 1.06秒 |
TableStructureRecognizer | 0.11秒 |
TextDetector | 2.73秒 |
TextRecognizer | 0.08秒 |
合計 | 3.28秒 |
エラーなく正常終了(約3秒で処理完了)
出力されたMarkdownファイルは空
可視化画像にも誤検出なし(スープの湯気や麺を文字と誤認したりしない)
学び
文字がない画像を入れても破綻しないのは実用上ありがたい挙動です。バッチ処理で大量画像を流すような業務でも安心して使えそうです。
検証②:テキストエディタ画面を撮影してみる
見せ場:「画面UIやノイズは文字として誤認識される」
青空文庫の『蜘蛛の糸』をテキストエディタで開き、そのディスプレイをスマホで撮影した画像で検証しました。
結果
認識された文字自体は部分的に正しかったものの、以下の問題が発生しました。
メニューバーやウインドウのUIが文字として認識された
青空文庫txt独自の外字注記(例:
※【#「特のへん+ん+車」、第3水準1-87-71】陀多)がそのまま文字として読み取られた段落順にも乱れが見られた

学び
画面上の余計な要素は容赦なく文字として拾われます。メニューバー、ウインドウ枠、ブックマークバーなど、人間は「これは読み取り対象ではない」と判断できても、AIは区別してくれません。OCRにかける画像は、読み取りたい文字以外の要素を極力入れないほうが良いという当たり前の教訓を再確認しました。
検証③:本来の用途にピッタリな画像で試す
見せ場:「得意分野の素材なら高精度」
検証②の反省を踏まえ、同じ『蜘蛛の糸』を縦書きレイアウトで表示できるWebサービス(「えあ草紙」)で開いて撮影しました。

結果
冒頭から作品通りの順序で出力された
ふりがな(ルビ)も認識
「蛙」「縋」などの難字も正しく認識
句読点・カギカッコも正確

ただし「犍陀多」のような異体字は苦手で、「健陀多」「雑陀多」「腱陀多」と表記揺れが発生しました。
学び
YomiTokuは日本語の紙面レイアウトを想定した画像が得意。UIなどの余計な要素がなく、文章がはっきり読める画像なら、かなり高精度に読み取ってくれます。
検証④:手書きメモで意外な現象に出会う
見せ場:「書き方向で出力順序が変わった」
手書き文字の認識精度を見たくて、隣の席の同僚に3行の簡単なメモを横書きで書いてもらいました。
※「ジャ●ンキー」の●は、「ン」を書き損じたため本人が塗りつぶした箇所。それ以外は誤字なし。


結果:順序が逆転した
出力されたMarkdownを見て驚きました。
書いた順序が完全に逆転していました。
文字認識の精度はこんな感じでした。
行 | 正解 | YomiToku出力 | 判定 |
|---|---|---|---|
1行目 | 今日は朝ご飯を食べました。 | 今日は朝ご飯も食べました。 | 「を」→「も」 |
2行目 | パン2枚にハンバーグとチーズ... | パン2枚にハンバーグセチーズ... | 「と」→「セ」 |
3行目 | ジャ●ンキーで美味しかった! | ジャカンキーで美味しかった! |
|
漢字(朝・飯・食・枚・美味)は全部正解する一方で、字形の似た平仮名・カタカナで誤認識が発生。そして塗りつぶしは文字として解釈されることがわかりました。
仮説を立てて追試:縦書きで同じ文章を書いてみる
順序の逆転に興味を持ったので、「書き方向が影響しているのでは?」と仮説を立てて、同じ3行を筆者自身が縦書きで書き直しました。

結果:
行の順序は書いた順通りに出力されました(上から1行目→2行目→3行目)。ただし、文字認識は検証④冒頭の横書きメモ(隣の人の字)より誤認識が多い結果に。これは筆者自身の字が汚いことも要因として考えられます。AI-OCRの精度は書き手の字の読みやすさにも左右されるという当たり前の事実が、身をもってわかりました。
また、撮影時に紙の上に置いていた充電ケーブルが文字として誤認識されるという副次的な発見もありました。出力の冒頭にある「アイティスドライブランド(1)(1)(1)(1)(1)(1)」という謎の文字列がそれで、ケーブルのうねった形状をAIが文字列として検出したようです。
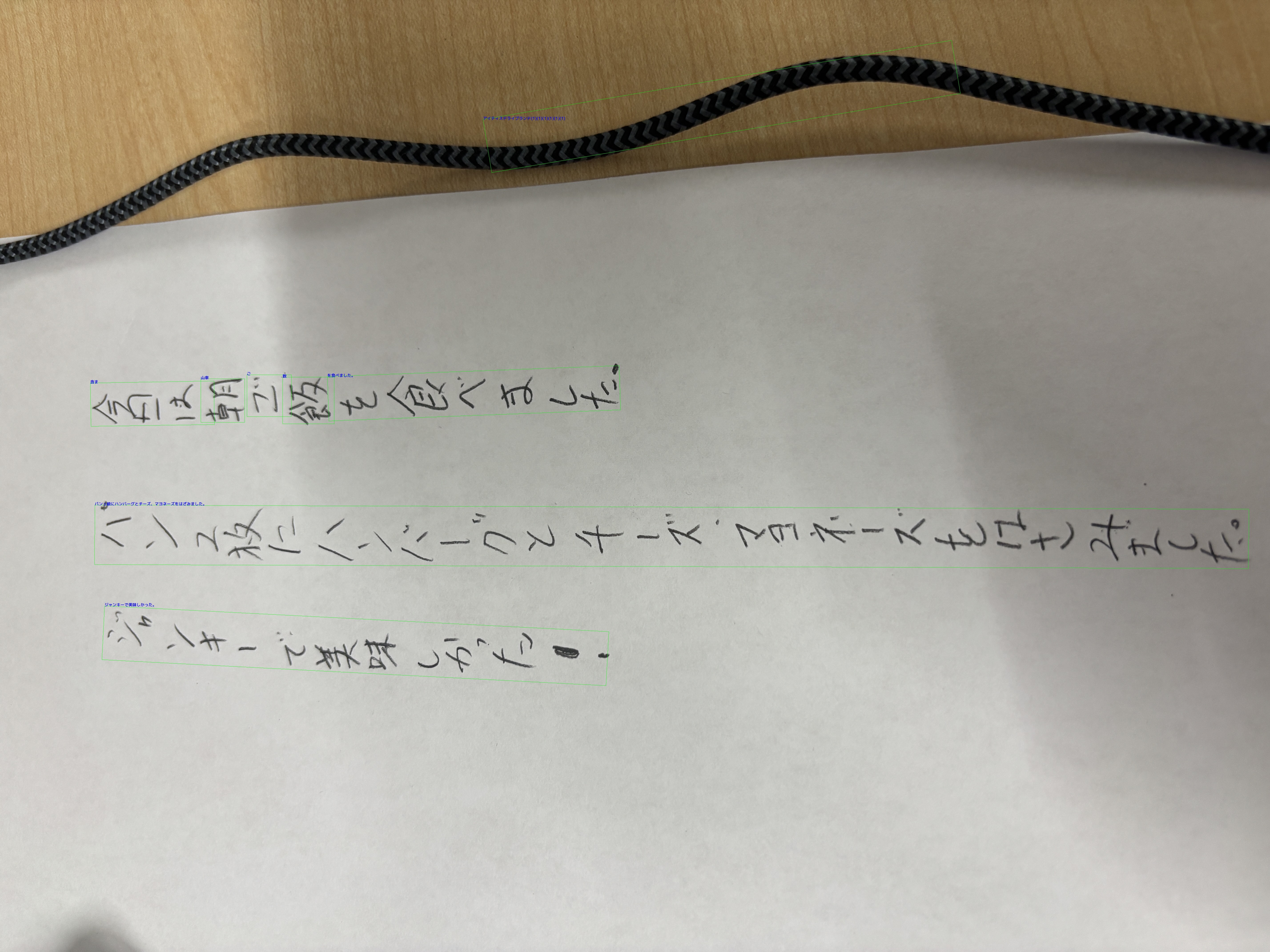

さらに追試:書き手を揃えて横書きを試す
書き手の影響を排除するため、筆者自身が今度は横書きで同じ3行を書きました。


結果:
筆者自身が書いた場合でも、再び順序が逆転しました。
学び
同じ3行を書き方向だけ変えて試した結果、書き方向によって出力順序が変わるという現象が、書き手に関わらず再現されました。
検証⑤:短文だから起きた問題なのか?
「長文でも同じ傾向が再現された」
検証④は3行の短い手書きメモでの話でした。「短文だから起きた問題なのでは?」という疑問が残ります。そこで、長文の横書き素材でも同じ現象が起きるか追加検証しました。
素材
青空文庫の『羅生門』(横書きHTML版)をPC画面に表示し、冒頭から数段落分をスマホで撮影しました。他の検証と撮影方法を揃えるため、PCスクショではなくスマホ撮影にしています。
URL:https://www.aozora.gr.jp/cards/000879/files/127_15260.html

結果
mdでの出現順 | 内容 | 実際の物語での位置 |
|---|---|---|
1番目 | 「下人はそこで、腰にさげた...」 | 物語の後半 |
中盤 | 「下人は、大きな曜をして...」 | 物語の後半 |
中盤 | 「雨は、羅生門をつつんで...」 | 物語の中盤 |
中盤 | 「作者はさっき、下人が雨やみを...」 | 物語の中盤 |
中盤 | 「その代りまた鶏がどこからか...」 | 物語の冒頭直後 |
後半 | 「ある日の暮方の事である」 | 物語の冒頭 |
物語の冒頭「ある日の暮方の事である」が、mdでは後半に出力されるという、3行メモと同じ逆転現象が発生しました。
一方で文字認識自体は高精度で、「羅生門」「朱雀大路」「Sentimentalisme」(外国語表記)まで読み取れていました。
学び
3行の手書きでも、長文のHTMLでも、同じ傾向が再現されたことで、偶然ではない挙動であることが確認できました。
今回の検証で見えたこと
結果の一覧
検証 | 書き方向 | 出力順序 |
|---|---|---|
検証③『蜘蛛の糸』HTML | 縦書き | ✅ 正順 |
検証④隣の人の手書き | 横書き | ❌ 逆順 |
検証④筆者の手書き | 縦書き | ✅ 正順 |
検証④筆者の手書き | 横書き | ❌ 逆順 |
検証⑤『羅生門』HTML | 横書き | ❌ 逆順 |
縦書きは正順、横書きは逆順という傾向が、書き手・文字量を変えても再現されました。
その他の発見
画面UI(メニューバー、ブックマークバー等)や紙の上の異物(ケーブル等)は文字として誤認識される
手書き文字でも漢字の認識精度は高い
字形の似た平仮名・カタカナ(を/も、と/セなど)では誤認識が起きやすい
塗りつぶしは文字として解釈される場合がある
今後の検証課題
今回は原因の厳密な特定までは踏み込んでいません。公式ドキュメントによればYomiTokuには --reading_order オプション(auto / top2bottom / left2right / right2left)があり、これを明示指定することで挙動が変わる可能性があります。実運用で使う場合はオプション指定も含めて検証する価値がありそうです。
その他、今回試せなかった課題:
英語文書での認識精度(公式は対応を明記)
Extractor機能を使った構造化データ抽出
所感
今回の検証で最も印象に残ったのは、書き方向によって出力結果が大きく変わるという点でした。「日本語OCR」と聞くと文字を読み取ってくれるだけのツールというイメージでしたが、実際には読み取った文字をどう並べて出力するかという部分にも個性があります。
実務で使うなら、YomiTokuは「与えれば何でも読んでくれる万能ツール」ではなく、入力する画像の状態を意識して使うツールと捉えるのが現実的だと感じました。特に、出力結果を別システムに流し込むパイプラインを組むなら、出力順序の確認処理をセットで用意しておくことが必要になりそうです。
次回は残った検証課題、特に--reading_orderオプションの挙動確認や、Extractor機能を使った構造化データ抽出に取り組んでみたいと思います。
→ 【次の記事】無料の日本語OCR「YomiToku」は、Claudeとどこまで戦えるのか
参考リンク
本記事はYomiToku OSS版(v0.12.0)で検証した結果に基づきます。環境・バージョンによって挙動が異なる可能性があります。
日本語OCR「YomiToku」を触ってみた:書き方向で結果が変わる話
はじめに
日本語に特化したAI-OCRエンジン「YomiToku」をご存じでしょうか。GitHubで公開されているOSSで、日本語の文書画像解析に特化した国産のドキュメントAIです。
今回、実務で使えそうか検証するためにMacに環境を構築し、いろんな画像でOCRを試してみました。色々触ってみた結果、ちょっと意外な発見があったので、失敗も含めてまとめておきます。
YomiTokuとは
日本語特化のAI文書画像解析エンジン(Document AI)です。画像からの全文OCRに加えて、レイアウト解析・表構造認識まで一貫して行ってくれます。
主な特徴
日本語データセットで独自学習された4つのAIモデルを搭載
文字位置の検知(TextDetector)
文字列認識(TextRecognizer)
レイアウト解析(LayoutParser)
表構造認識(TableStructureRecognizer)
7000字を超える日本語文字に対応、縦書き・手書きもサポート
英語の文書にも対応
出力形式はHTML/Markdown/JSON/CSV/サーチャブルPDF
VRAM 8GB以内で動作、軽量モデルならCPUでも実用的
※ 公式ドキュメントでは、看板など紙以外にプリントされた文字の読み取り(情景OCR)は最適化対象外と明記されています。
⚠️ ライセンスに注意
OSS版は CC BY-NC-SA 4.0 ライセンスです。非商用(個人・学術・研究)は自由ですが、商用利用には別途ライセンス契約が必要です。クライアント案件や業務での本番利用を検討する場合は、開発元のmlism社またはAWS Marketplace版(YomiToku-Pro)を検討してください。
本記事は技術検証目的の非商用利用として実施しています。
環境構築(macOS)
前提
Python 3.10以上(今回は 3.13.1)
macOS(Apple Silicon / Intel どちらでもOK)
手順
# 作業フォルダ作成 mkdir ~/yomitoku-test cd ~/yomitoku-test # 仮想環境作成&有効化 python3 -m venv .venv source .venv/bin/activate # YomiTokuインストール
依存パッケージとしてPyTorch・ONNX Runtime・Transformers・OpenCV・pdf2imageなどが自動で入ります。合計数百MBなので少し時間がかかります。
基本の実行コマンド
yomitoku input.jpg -f md -v -o
-f md:Markdown形式で出力-v:可視化画像を出力-o results:出力先フォルダ指定
初回実行時はHugging Face Hubから4種類のモデルファイル(合計約650MB)が自動ダウンロードされます。
出力されるファイルの見方
yomitoku input.jpg -f md -v -o results を実行すると、resultsディレクトリに以下のファイルが生成されます。
ファイル | 中身 |
|---|---|
| 入力画像のコピー(何も加工されていない元画像) |
| レイアウト解析の可視化画像 |
| OCR結果の可視化画像 |
| 読み取ったテキスト(Markdown形式) |
可視化画像の凡例(公式より)
赤枠:図、画像等の位置
緑枠:表領域全体の位置
ピンク枠:表のセル構造
青枠:段落、テキストグループ領域
赤矢印:読み順推定の結果
今回遭遇した現象:可視化画像が横向きになる
今回の検証では、入力画像は縦向きなのに、出力される可視化画像(layout.jpg / ocr.jpg)だけが横向きになる現象が発生しました。入力画像のコピー(_xxx_p1.jpg)とMarkdown出力は正しい向きのままなので、認識結果自体には影響しませんが、可視化画像を確認する際は頭の中で90度回転させて見る必要がありました。
以降の検証で可視化画像を貼っている箇所は、この現象が起きた状態のままで掲載しています。
検証①:文字のない画像を入れてみる
見せ場:「文字なし画像でもエラーで落ちない」
まず、文字がまったく写っていないラーメンの写真で挙動を確認しました。実運用では「文字がない画像が誤って混ざっていた」というケースもあり得るので、エラー耐性を見る意味で重要なテストです。
結果
処理 | 時間 |
|---|---|
LayoutParser | 1.06秒 |
TableStructureRecognizer | 0.11秒 |
TextDetector | 2.73秒 |
TextRecognizer | 0.08秒 |
合計 | 3.28秒 |
エラーなく正常終了(約3秒で処理完了)
出力されたMarkdownファイルは空
可視化画像にも誤検出なし(スープの湯気や麺を文字と誤認したりしない)
学び
文字がない画像を入れても破綻しないのは実用上ありがたい挙動です。バッチ処理で大量画像を流すような業務でも安心して使えそうです。
検証②:テキストエディタ画面を撮影してみる
見せ場:「画面UIやノイズは文字として誤認識される」
青空文庫の『蜘蛛の糸』をテキストエディタで開き、そのディスプレイをスマホで撮影した画像で検証しました。
結果
認識された文字自体は部分的に正しかったものの、以下の問題が発生しました。
メニューバーやウインドウのUIが文字として認識された
青空文庫txt独自の外字注記(例:
※【#「特のへん+ん+車」、第3水準1-87-71】陀多)がそのまま文字として読み取られた段落順にも乱れが見られた
学び
画面上の余計な要素は容赦なく文字として拾われます。メニューバー、ウインドウ枠、ブックマークバーなど、人間は「これは読み取り対象ではない」と判断できても、AIは区別してくれません。OCRにかける画像は、読み取りたい文字以外の要素を極力入れないほうが良いという当たり前の教訓を再確認しました。
検証③:本来の用途にピッタリな画像で試す
見せ場:「得意分野の素材なら高精度」
検証②の反省を踏まえ、同じ『蜘蛛の糸』を縦書きレイアウトで表示できるWebサービス(「えあ草紙」)で開いて撮影しました。
結果
冒頭から作品通りの順序で出力された
ふりがな(ルビ)も認識
「蛙」「縋」などの難字も正しく認識
句読点・カギカッコも正確
ただし「犍陀多」のような異体字は苦手で、「健陀多」「雑陀多」「腱陀多」と表記揺れが発生しました。
学び
YomiTokuは日本語の紙面レイアウトを想定した画像が得意。UIなどの余計な要素がなく、文章がはっきり読める画像なら、かなり高精度に読み取ってくれます。
検証④:手書きメモで意外な現象に出会う
見せ場:「書き方向で出力順序が変わった」
手書き文字の認識精度を見たくて、隣の席の同僚に3行の簡単なメモを横書きで書いてもらいました。
※「ジャ●ンキー」の●は、「ン」を書き損じたため本人が塗りつぶした箇所。それ以外は誤字なし。
結果:順序が逆転した
出力されたMarkdownを見て驚きました。
書いた順序が完全に逆転していました。
文字認識の精度はこんな感じでした。
行 | 正解 | YomiToku出力 | 判定 |
|---|---|---|---|
1行目 | 今日は朝ご飯を食べました。 | 今日は朝ご飯も食べました。 | 「を」→「も」 |
2行目 | パン2枚にハンバーグとチーズ... | パン2枚にハンバーグセチーズ... | 「と」→「セ」 |
3行目 | ジャ●ンキーで美味しかった! | ジャカンキーで美味しかった! |
|
漢字(朝・飯・食・枚・美味)は全部正解する一方で、字形の似た平仮名・カタカナで誤認識が発生。そして塗りつぶしは文字として解釈されることがわかりました。
仮説を立てて追試:縦書きで同じ文章を書いてみる
順序の逆転に興味を持ったので、「書き方向が影響しているのでは?」と仮説を立てて、同じ3行を筆者自身が縦書きで書き直しました。
結果:
行の順序は書いた順通りに出力されました(上から1行目→2行目→3行目)。ただし、文字認識は検証④冒頭の横書きメモ(隣の人の字)より誤認識が多い結果に。これは筆者自身の字が汚いことも要因として考えられます。AI-OCRの精度は書き手の字の読みやすさにも左右されるという当たり前の事実が、身をもってわかりました。
また、撮影時に紙の上に置いていた充電ケーブルが文字として誤認識されるという副次的な発見もありました。出力の冒頭にある「アイティスドライブランド(1)(1)(1)(1)(1)(1)」という謎の文字列がそれで、ケーブルのうねった形状をAIが文字列として検出したようです。
さらに追試:書き手を揃えて横書きを試す
書き手の影響を排除するため、筆者自身が今度は横書きで同じ3行を書きました。
結果:
筆者自身が書いた場合でも、再び順序が逆転しました。
学び
同じ3行を書き方向だけ変えて試した結果、書き方向によって出力順序が変わるという現象が、書き手に関わらず再現されました。
検証⑤:短文だから起きた問題なのか?
「長文でも同じ傾向が再現された」
検証④は3行の短い手書きメモでの話でした。「短文だから起きた問題なのでは?」という疑問が残ります。そこで、長文の横書き素材でも同じ現象が起きるか追加検証しました。
素材
青空文庫の『羅生門』(横書きHTML版)をPC画面に表示し、冒頭から数段落分をスマホで撮影しました。他の検証と撮影方法を揃えるため、PCスクショではなくスマホ撮影にしています。
URL:https://www.aozora.gr.jp/cards/000879/files/127_15260.html
結果
mdでの出現順 | 内容 | 実際の物語での位置 |
|---|---|---|
1番目 | 「下人はそこで、腰にさげた...」 | 物語の後半 |
中盤 | 「下人は、大きな曜をして...」 | 物語の後半 |
中盤 | 「雨は、羅生門をつつんで...」 | 物語の中盤 |
中盤 | 「作者はさっき、下人が雨やみを...」 | 物語の中盤 |
中盤 | 「その代りまた鶏がどこからか...」 | 物語の冒頭直後 |
後半 | 「ある日の暮方の事である」 | 物語の冒頭 |
物語の冒頭「ある日の暮方の事である」が、mdでは後半に出力されるという、3行メモと同じ逆転現象が発生しました。
一方で文字認識自体は高精度で、「羅生門」「朱雀大路」「Sentimentalisme」(外国語表記)まで読み取れていました。
学び
3行の手書きでも、長文のHTMLでも、同じ傾向が再現されたことで、偶然ではない挙動であることが確認できました。
今回の検証で見えたこと
結果の一覧
検証 | 書き方向 | 出力順序 |
|---|---|---|
検証③『蜘蛛の糸』HTML | 縦書き | ✅ 正順 |
検証④隣の人の手書き | 横書き | ❌ 逆順 |
検証④筆者の手書き | 縦書き | ✅ 正順 |
検証④筆者の手書き | 横書き | ❌ 逆順 |
検証⑤『羅生門』HTML | 横書き | ❌ 逆順 |
縦書きは正順、横書きは逆順という傾向が、書き手・文字量を変えても再現されました。
その他の発見
画面UI(メニューバー、ブックマークバー等)や紙の上の異物(ケーブル等)は文字として誤認識される
手書き文字でも漢字の認識精度は高い
字形の似た平仮名・カタカナ(を/も、と/セなど)では誤認識が起きやすい
塗りつぶしは文字として解釈される場合がある
今後の検証課題
今回は原因の厳密な特定までは踏み込んでいません。公式ドキュメントによればYomiTokuには --reading_order オプション(auto / top2bottom / left2right / right2left)があり、これを明示指定することで挙動が変わる可能性があります。実運用で使う場合はオプション指定も含めて検証する価値がありそうです。
その他、今回試せなかった課題:
英語文書での認識精度(公式は対応を明記)
Extractor機能を使った構造化データ抽出
所感
今回の検証で最も印象に残ったのは、書き方向によって出力結果が大きく変わるという点でした。「日本語OCR」と聞くと文字を読み取ってくれるだけのツールというイメージでしたが、実際には読み取った文字をどう並べて出力するかという部分にも個性があります。
実務で使うなら、YomiTokuは「与えれば何でも読んでくれる万能ツール」ではなく、入力する画像の状態を意識して使うツールと捉えるのが現実的だと感じました。特に、出力結果を別システムに流し込むパイプラインを組むなら、出力順序の確認処理をセットで用意しておくことが必要になりそうです。
次回は残った検証課題、特に--reading_orderオプションの挙動確認や、Extractor機能を使った構造化データ抽出に取り組んでみたいと思います。
→ 【次の記事】無料の日本語OCR「YomiToku」は、Claudeとどこまで戦えるのか
参考リンク
本記事はYomiToku OSS版(v0.12.0)で検証した結果に基づきます。環境・バージョンによって挙動が異なる可能性があります。

AI・システム開発のこと、VISKにご相談ください
「自社の業務にAIを活かせないか」「この作業、自動化できないか」——
そんな漠然とした段階からで大丈夫です。大阪のAI・システム開発会社VISKが、御社の課題に合わせて、企画から開発・検証までサポートします。
