ブラウザだけで動くAI映像認識 SmolVLMの実力を検証してみた
ブラウザだけで動くAI映像認識 SmolVLMの実力を検証してみた

500円のカメラアプリより賢い?ブラウザだけで動くAI映像認識「SmolVLM」を本気で検証してみた
「カメラに映っているものを、AIがリアルタイムで説明してくれる」
SF映画の話ではありません。サーバー不要、ブラウザだけで動く時代がもう来ています。
今回検証したのは、Hugging Faceが公開している SmolVLM-realtime-webcam。わずか500Mパラメータという超軽量モデルで、Webカメラの映像をAIがリアルタイムで認識・解説してくれるデモアプリです。
「軽量モデルで、どこまで実用的な認識ができるのか?」——期待と不安を抱えながら、実際に動かしてみました。
そもそもSmolVLMって何?
SmolVLMは、Hugging Faceが開発した**軽量ビジョン言語モデル(VLM)**です。
パラメータ数: 500M(GPT-4Vと比べると桁違いに小さい)
動作環境: llama.cppサーバー + ブラウザ(ローカルPC上で完結)
できること: Webカメラの映像を見て、「何が映っているか」を自然言語で説明
GitHub: ngxson/smolvlm-realtime-webcam(★4.7k)
クラウドAPIに頼らず、手元のPCだけでリアルタイム映像認識ができる。それがSmolVLMの最大の魅力です。
検証環境
項目 | 内容 |
|---|---|
PC | Mac |
ブラウザ | Chrome |
モデル | SmolVLM-500M-Instruct(GGUF形式) |
バックエンド | llama.cpp server |
入力デバイス | 内蔵Webカメラ → スマホカメラ(後述) |
検証前の小さな戦い:スクショが撮れない問題
検証を始めてすぐ、地味な壁にぶつかりました。
まず、SmolVLMの回答は基本的に英語で返ってくるので、DeepLを横に開いて翻訳しながらの検証になります。
そして、色々な角度からカメラに映したい。上からの画角を試そうと、スマホを高く掲げて撮影し、「よし、今だ!」とCommand+Shift+3でスクショを撮ったら——DeepLのウィンドウが閉じました。
「これはもう、スマホをWebカメラとして使った方がいいんじゃないか?」
そう思い立ち、スマホカメラとPCの連携を設定。見事に成功。 手元で自由にアングルを変えられるようになり、意気揚々と検証を再開したのですが……
片手でスマホを持ちながら、もう片方の手でCommand+Shift+3を押すほうが、圧倒的に難しかった。
3つのキーを同時押し。人間の手が2本しかない以上、物理的に無理があります。「実装してから気づく残念な事実」、エンジニアなら一度は経験があるのではないでしょうか。
6つのテストで実力を丸裸にしてみた
気を取り直して、SmolVLMの認識精度を6つのテストで徹底検証しました。
テスト1:環境認識(オフィスの風景) → ◎ 優秀!
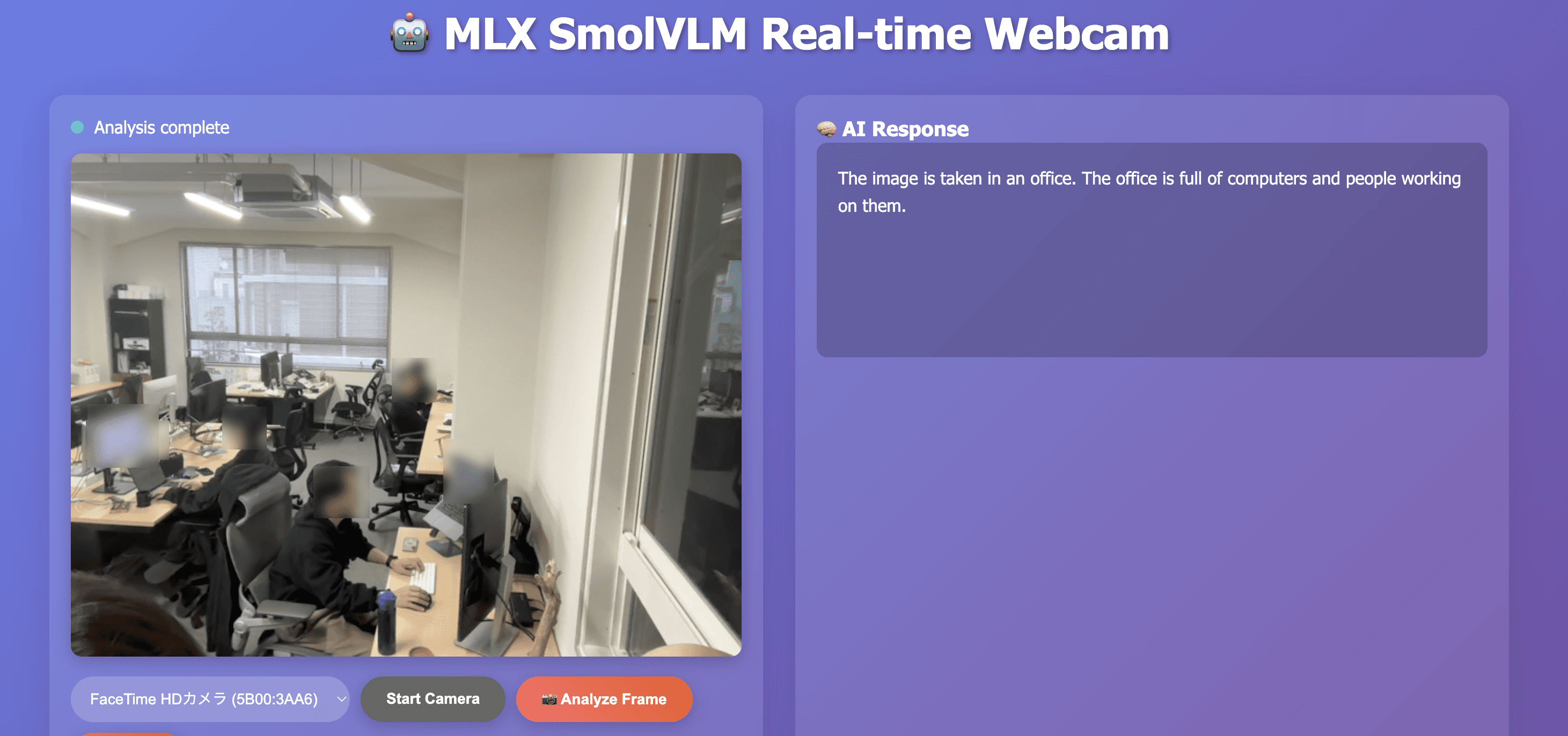
カメラに映るオフィス環境を、どの程度正確に説明できるか。
結果は期待以上でした。
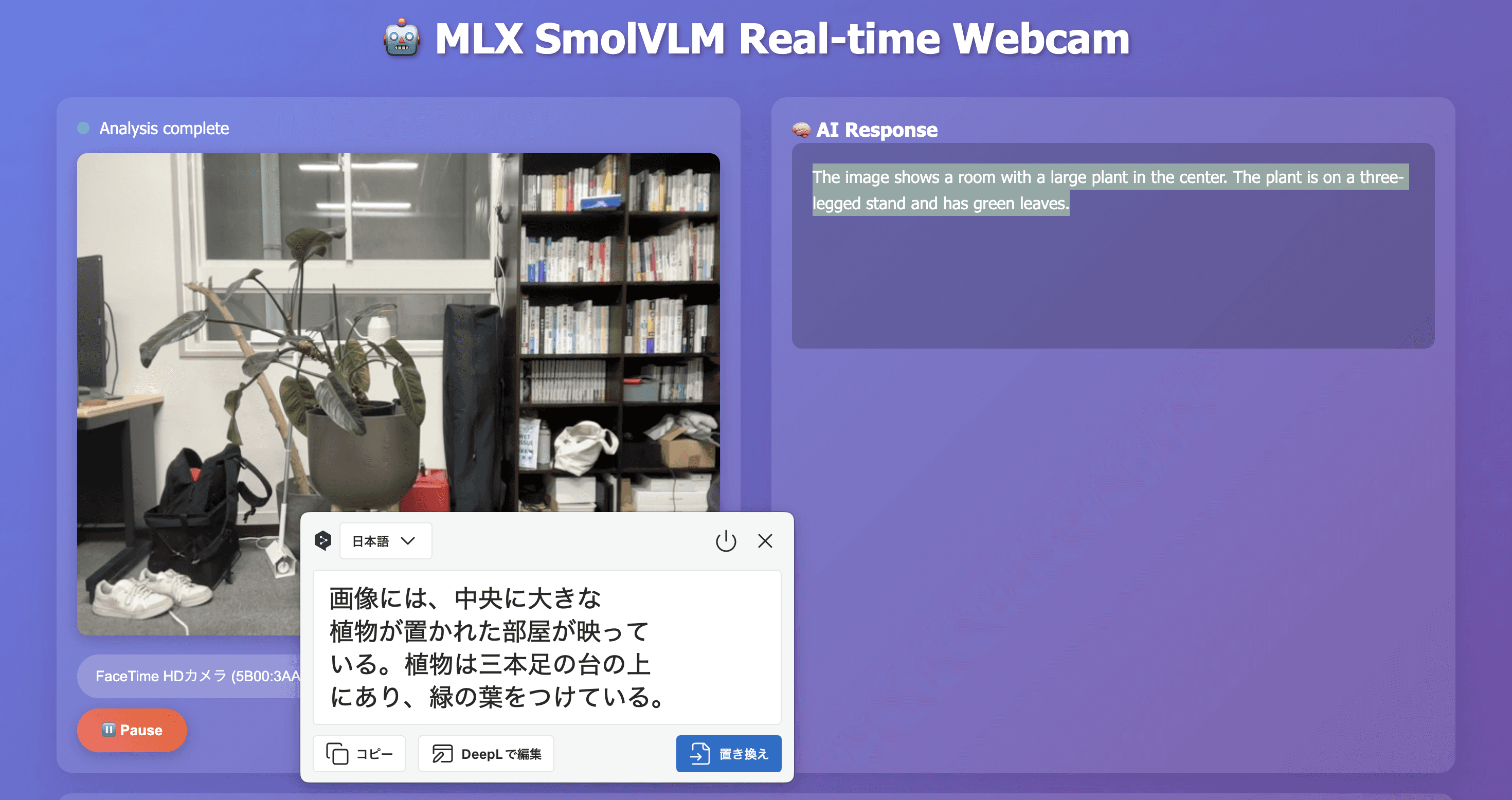
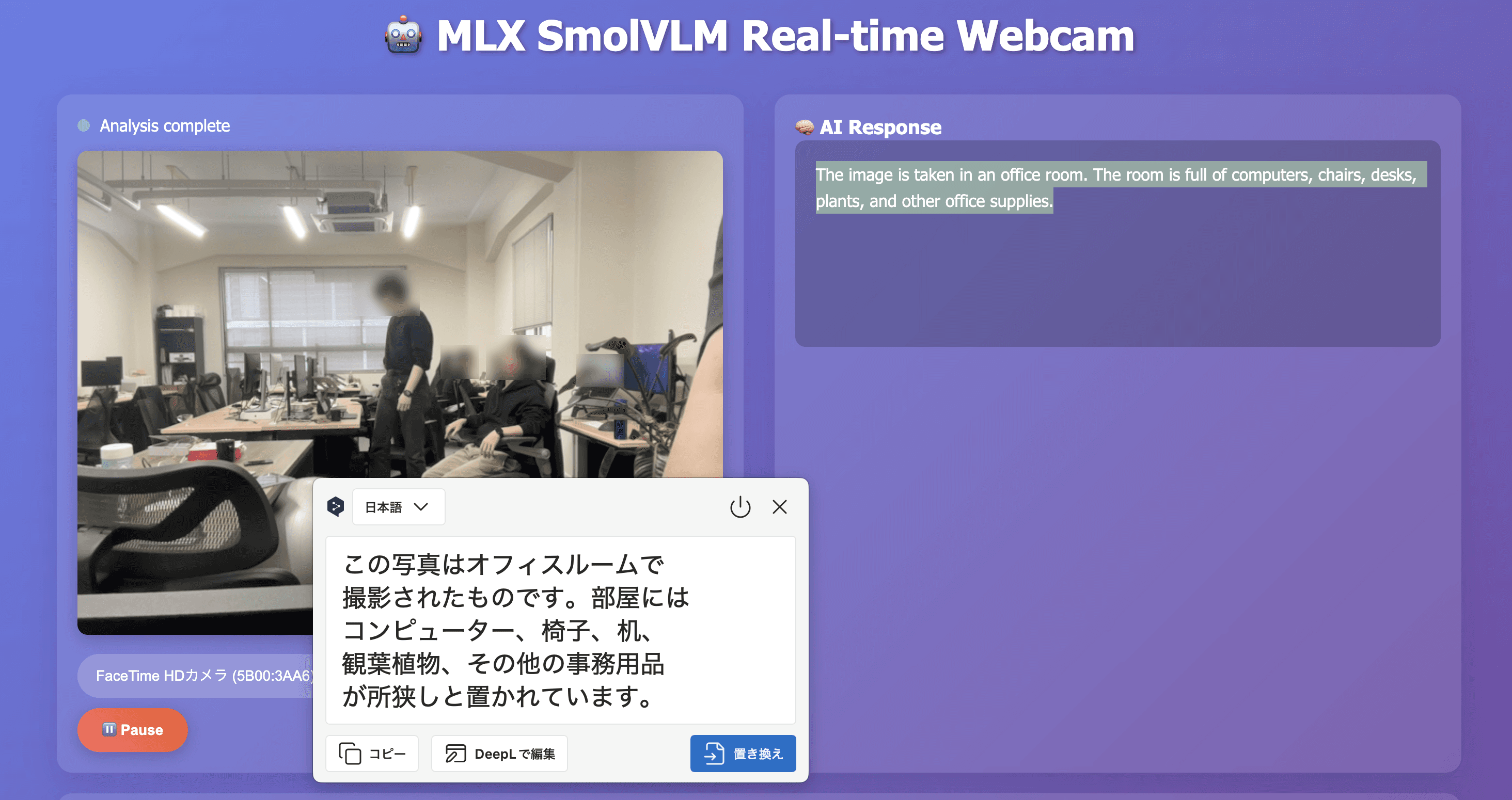
デスク、モニター、椅子、観葉植物などを正しく認識し、「オフィス環境でデスクワークをしている」という文脈まで理解。照明が変わっても安定していました。
「500Mでこれだけできるのか」と、正直驚きました。
テスト2:人物カウント → △ ちょっと怪しい
1人なら正確。でも2人以上になると……「何人かいる」程度の認識にとどまりました。正確な人数を数えるのは苦手なようです。
テスト3:服装の認識 → △ 日替わりで回答が変わる
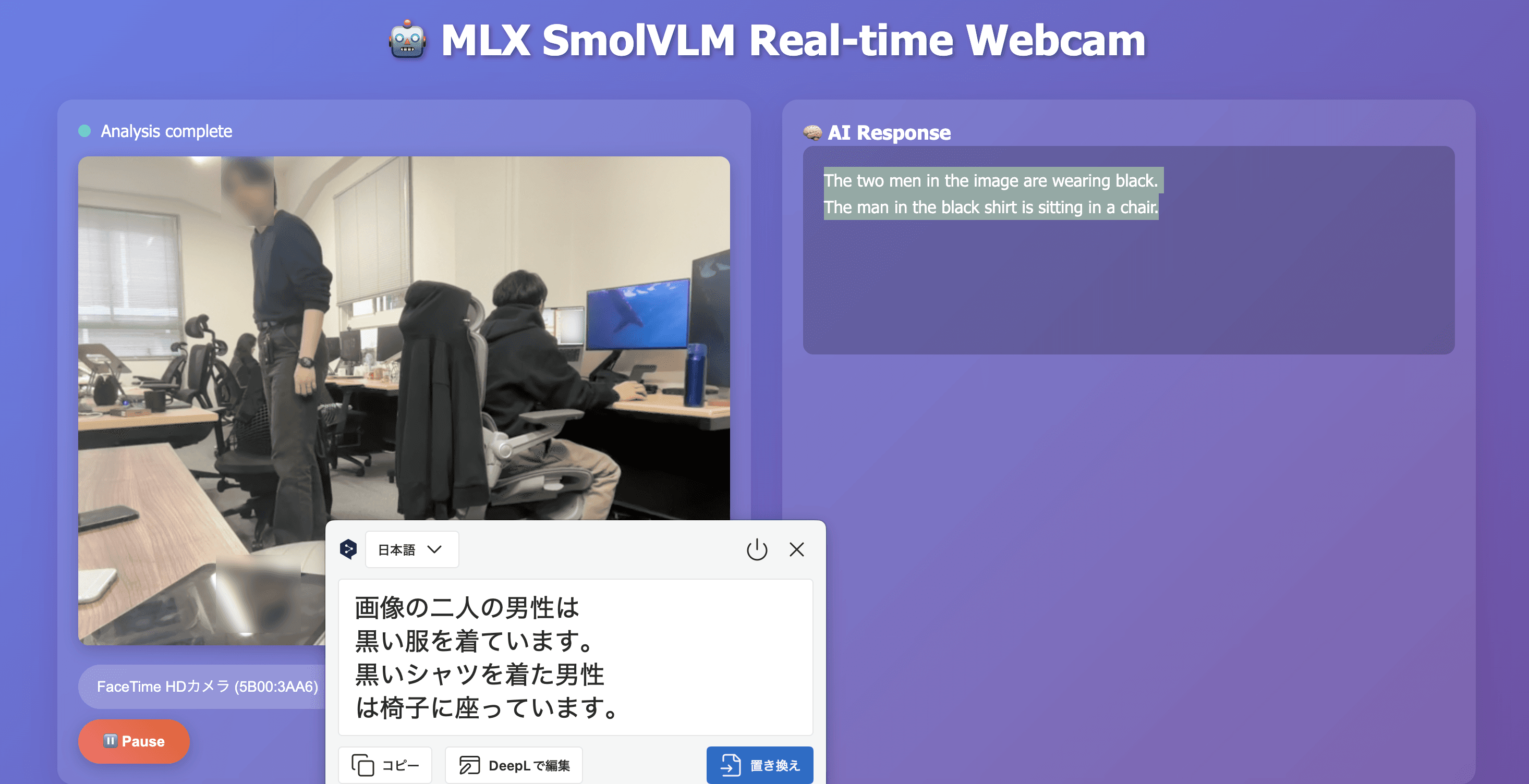
同じ服装でもタイミングによって回答が変わります。大まかな色は認識できますが、服の種類を正確に当てるのは難しいようです。
テスト4:物体認識の精度 → △ 数も種類も盛ってくる
📸 電子レンジとコーヒーメーカーが「オーブン2台とトースターオーブン」に変身。数も種類も盛ってくるのがSmolVLMの個性。 (※写真⑤:電子レンジをオーブンと誤認識している画像)
似たカテゴリの物体(キッチン家電同士など)を混同する傾向があります。「だいたい合ってるけど、細部が違う」という感じです。
テスト5:ジェスチャー認識 → × 反応なし
手を挙げてみたり、ピースサインをしてみたり。ほぼ反応なし。 認識できるときもあるにはあるのですが、一貫性がなく、実用には程遠い結果でした。
テスト6:回答の一貫性 → × 毎回言うことが違う
これが一番気になったポイントです。同じカメラアングルで同じ場面を映しているのに、毎回違う回答が返ってくる。
「1人います」→ 次の瞬間「2人います」。何も変わっていないのに。
そして極めつけがこちら。
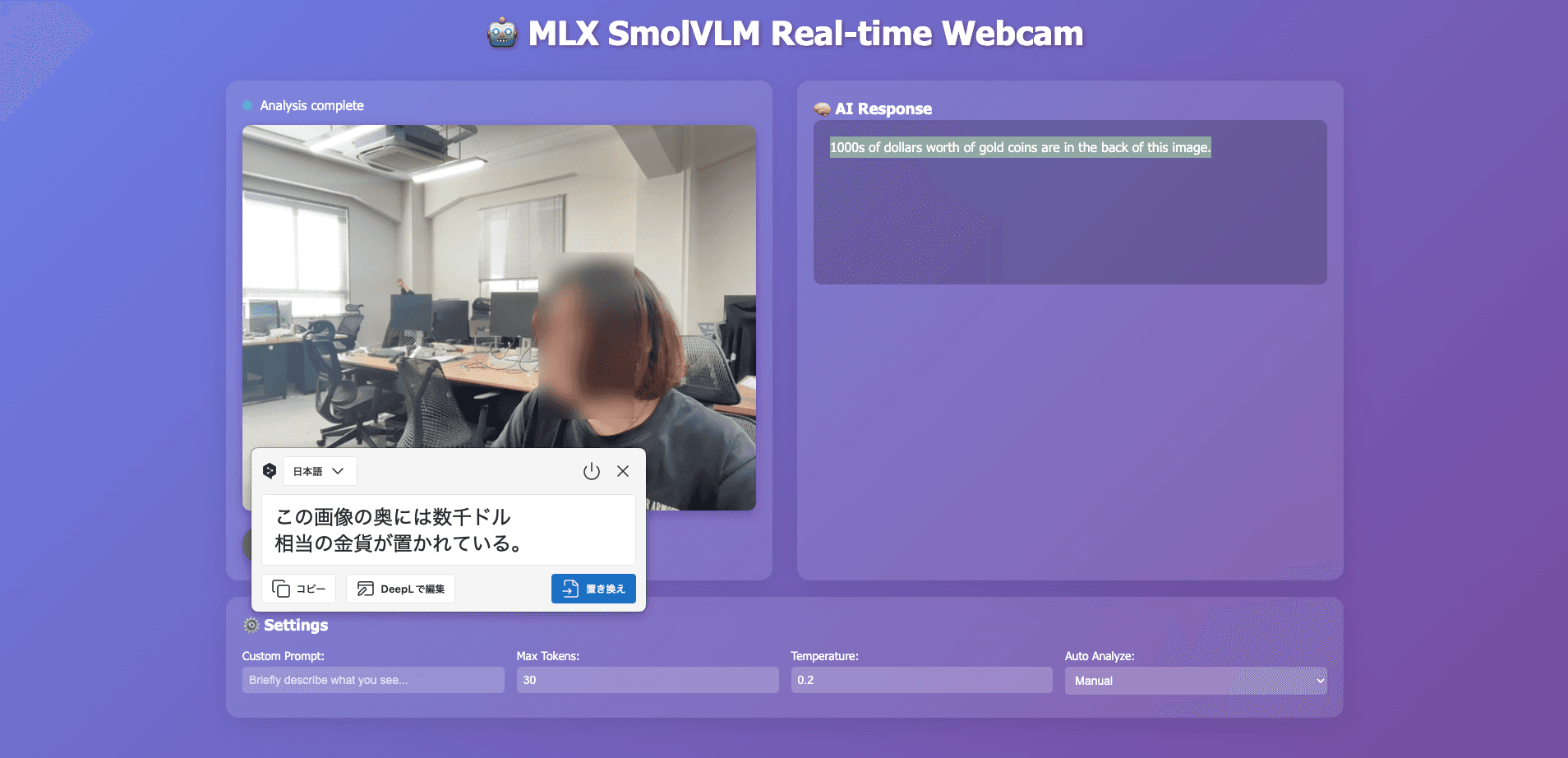
ないものが見える。 これがAIの「ハルシネーション(幻覚)」です。軽量モデルでは特に起こりやすい現象で、SmolVLM-500Mでもはっきり確認できました。VISKの未来が見えているかもしれません。
テスト7:応答速度 → ○ これは十分
数秒間隔でレスポンスが返ります。リアルタイムモニタリングとしては十分な速度。ここはしっかり合格点です。
検証結果を一枚の表にまとめると
テスト項目 | 評価 | ひとこと |
|---|---|---|
環境認識 | ◎ | 「オフィスで仕事中」まで理解する |
人物カウント | △ | 1人はOK、2人以上は怪しい |
服装認識 | △ | 色はわかる、種類は気分次第 |
物体認識 | △ | 似たカテゴリの物を混同する |
ジェスチャー認識 | × | ピースしても無視される |
回答の一貫性 | × | 同じ場面なのに毎回違うことを言う |
応答速度 | ○ | 数秒で返ってくる、これは優秀 |
500Mパラメータの「できること」と「できないこと」
得意なこと 💪
シーン全体のざっくり把握: 「オフィスで人が仕事をしている」レベルの理解は非常に正確
一般的な物体の認識: デスク、モニター、椅子、観葉植物くらいなら余裕
応答速度: ローカル実行で数秒。クラウドAPI不要でこの速さは立派
苦手なこと 😅
数を数える: 人数や物の個数はだいたい間違える
細かい動作: ジェスチャーや手の動きは認識が追いつかない
一貫性を保つ: 同じ場面でも「今日の気分」で回答が変わる
細部の判定: 服の種類や小さな物体の識別は厳しい
ハルシネーション: 存在しないものを堂々と報告してくる
じゃあ、どこで使える?
✅ 向いている用途
会議室の空き確認 — 「人がいる or いない」の二択なら十分な精度
ざっくり環境モニタリング — 異常な状態(誰もいないはずの場所に人影)の検知
デモ・プロトタイプ — 「AIカメラってこういうことができます」の概念実証
❌ 向いていない用途
入退室管理 — 正確な人数カウントが必要な場面には力不足
セキュリティ監視 — 細かい動作の認識ができないと意味がない
品質検査 — ミリ単位の精度が求められる現場には到底及ばない
金貨の鑑定 — 言うまでもなく
まとめ:「ざっくり理解」の天才、「正確さ」は今後に期待
SmolVLM-500Mは、ブラウザとローカルPCだけでAIカメラ体験ができるという点では非常に手軽で魅力的なツールです。
ただし、検証の結論は明確でした。
「大まかなシーン理解は得意。でも正確さが求められる用途には向かない。」
特に回答の一貫性の低さとハルシネーションが最大の課題です。同じ場面を見せても毎回違うことを言い、挙げ句の果てに金貨が見えるAIは、業務では信頼しづらい。
とはいえ、これは500Mという超軽量モデルの話。2Bや7Bクラスのモデルならどうか、特定タスクにファインチューニングしたらどうか——まだまだ伸びしろはあります。
あ、あとスマホとPCの連携は、物理的な操作性まで考えてから実装しましょう。DeepLが吹き飛ぶのも、Command+Shift+3が押せないのも、全部「やってから気づく」系の罠です。これが今回一番の学びだったかもしれません。
検証環境:Mac / Chrome / SmolVLM-500M-Instruct / llama.cpp server / 2026年2月
VISK株式会社 | AI技術検証レポート
500円のカメラアプリより賢い?ブラウザだけで動くAI映像認識「SmolVLM」を本気で検証してみた
「カメラに映っているものを、AIがリアルタイムで説明してくれる」
SF映画の話ではありません。サーバー不要、ブラウザだけで動く時代がもう来ています。
今回検証したのは、Hugging Faceが公開している SmolVLM-realtime-webcam。わずか500Mパラメータという超軽量モデルで、Webカメラの映像をAIがリアルタイムで認識・解説してくれるデモアプリです。
「軽量モデルで、どこまで実用的な認識ができるのか?」——期待と不安を抱えながら、実際に動かしてみました。
そもそもSmolVLMって何?
SmolVLMは、Hugging Faceが開発した**軽量ビジョン言語モデル(VLM)**です。
パラメータ数: 500M(GPT-4Vと比べると桁違いに小さい)
動作環境: llama.cppサーバー + ブラウザ(ローカルPC上で完結)
できること: Webカメラの映像を見て、「何が映っているか」を自然言語で説明
GitHub: ngxson/smolvlm-realtime-webcam(★4.7k)
クラウドAPIに頼らず、手元のPCだけでリアルタイム映像認識ができる。それがSmolVLMの最大の魅力です。
検証環境
項目 | 内容 |
|---|---|
PC | Mac |
ブラウザ | Chrome |
モデル | SmolVLM-500M-Instruct(GGUF形式) |
バックエンド | llama.cpp server |
入力デバイス | 内蔵Webカメラ → スマホカメラ(後述) |
検証前の小さな戦い:スクショが撮れない問題
検証を始めてすぐ、地味な壁にぶつかりました。
まず、SmolVLMの回答は基本的に英語で返ってくるので、DeepLを横に開いて翻訳しながらの検証になります。
そして、色々な角度からカメラに映したい。上からの画角を試そうと、スマホを高く掲げて撮影し、「よし、今だ!」とCommand+Shift+3でスクショを撮ったら——DeepLのウィンドウが閉じました。
「これはもう、スマホをWebカメラとして使った方がいいんじゃないか?」
そう思い立ち、スマホカメラとPCの連携を設定。見事に成功。 手元で自由にアングルを変えられるようになり、意気揚々と検証を再開したのですが……
片手でスマホを持ちながら、もう片方の手でCommand+Shift+3を押すほうが、圧倒的に難しかった。
3つのキーを同時押し。人間の手が2本しかない以上、物理的に無理があります。「実装してから気づく残念な事実」、エンジニアなら一度は経験があるのではないでしょうか。
6つのテストで実力を丸裸にしてみた
気を取り直して、SmolVLMの認識精度を6つのテストで徹底検証しました。
テスト1:環境認識(オフィスの風景) → ◎ 優秀!
カメラに映るオフィス環境を、どの程度正確に説明できるか。
結果は期待以上でした。
デスク、モニター、椅子、観葉植物などを正しく認識し、「オフィス環境でデスクワークをしている」という文脈まで理解。照明が変わっても安定していました。
「500Mでこれだけできるのか」と、正直驚きました。
テスト2:人物カウント → △ ちょっと怪しい
1人なら正確。でも2人以上になると……「何人かいる」程度の認識にとどまりました。正確な人数を数えるのは苦手なようです。
テスト3:服装の認識 → △ 日替わりで回答が変わる
同じ服装でもタイミングによって回答が変わります。大まかな色は認識できますが、服の種類を正確に当てるのは難しいようです。
テスト4:物体認識の精度 → △ 数も種類も盛ってくる
📸 電子レンジとコーヒーメーカーが「オーブン2台とトースターオーブン」に変身。数も種類も盛ってくるのがSmolVLMの個性。 (※写真⑤:電子レンジをオーブンと誤認識している画像)
似たカテゴリの物体(キッチン家電同士など)を混同する傾向があります。「だいたい合ってるけど、細部が違う」という感じです。
テスト5:ジェスチャー認識 → × 反応なし
手を挙げてみたり、ピースサインをしてみたり。ほぼ反応なし。 認識できるときもあるにはあるのですが、一貫性がなく、実用には程遠い結果でした。
テスト6:回答の一貫性 → × 毎回言うことが違う
これが一番気になったポイントです。同じカメラアングルで同じ場面を映しているのに、毎回違う回答が返ってくる。
「1人います」→ 次の瞬間「2人います」。何も変わっていないのに。
そして極めつけがこちら。
ないものが見える。 これがAIの「ハルシネーション(幻覚)」です。軽量モデルでは特に起こりやすい現象で、SmolVLM-500Mでもはっきり確認できました。VISKの未来が見えているかもしれません。
テスト7:応答速度 → ○ これは十分
数秒間隔でレスポンスが返ります。リアルタイムモニタリングとしては十分な速度。ここはしっかり合格点です。
検証結果を一枚の表にまとめると
テスト項目 | 評価 | ひとこと |
|---|---|---|
環境認識 | ◎ | 「オフィスで仕事中」まで理解する |
人物カウント | △ | 1人はOK、2人以上は怪しい |
服装認識 | △ | 色はわかる、種類は気分次第 |
物体認識 | △ | 似たカテゴリの物を混同する |
ジェスチャー認識 | × | ピースしても無視される |
回答の一貫性 | × | 同じ場面なのに毎回違うことを言う |
応答速度 | ○ | 数秒で返ってくる、これは優秀 |
500Mパラメータの「できること」と「できないこと」
得意なこと 💪
シーン全体のざっくり把握: 「オフィスで人が仕事をしている」レベルの理解は非常に正確
一般的な物体の認識: デスク、モニター、椅子、観葉植物くらいなら余裕
応答速度: ローカル実行で数秒。クラウドAPI不要でこの速さは立派
苦手なこと 😅
数を数える: 人数や物の個数はだいたい間違える
細かい動作: ジェスチャーや手の動きは認識が追いつかない
一貫性を保つ: 同じ場面でも「今日の気分」で回答が変わる
細部の判定: 服の種類や小さな物体の識別は厳しい
ハルシネーション: 存在しないものを堂々と報告してくる
じゃあ、どこで使える?
✅ 向いている用途
会議室の空き確認 — 「人がいる or いない」の二択なら十分な精度
ざっくり環境モニタリング — 異常な状態(誰もいないはずの場所に人影)の検知
デモ・プロトタイプ — 「AIカメラってこういうことができます」の概念実証
❌ 向いていない用途
入退室管理 — 正確な人数カウントが必要な場面には力不足
セキュリティ監視 — 細かい動作の認識ができないと意味がない
品質検査 — ミリ単位の精度が求められる現場には到底及ばない
金貨の鑑定 — 言うまでもなく
まとめ:「ざっくり理解」の天才、「正確さ」は今後に期待
SmolVLM-500Mは、ブラウザとローカルPCだけでAIカメラ体験ができるという点では非常に手軽で魅力的なツールです。
ただし、検証の結論は明確でした。
「大まかなシーン理解は得意。でも正確さが求められる用途には向かない。」
特に回答の一貫性の低さとハルシネーションが最大の課題です。同じ場面を見せても毎回違うことを言い、挙げ句の果てに金貨が見えるAIは、業務では信頼しづらい。
とはいえ、これは500Mという超軽量モデルの話。2Bや7Bクラスのモデルならどうか、特定タスクにファインチューニングしたらどうか——まだまだ伸びしろはあります。
あ、あとスマホとPCの連携は、物理的な操作性まで考えてから実装しましょう。DeepLが吹き飛ぶのも、Command+Shift+3が押せないのも、全部「やってから気づく」系の罠です。これが今回一番の学びだったかもしれません。
検証環境:Mac / Chrome / SmolVLM-500M-Instruct / llama.cpp server / 2026年2月
VISK株式会社 | AI技術検証レポート

AI・システム開発のこと、VISKにご相談ください
「自社の業務にAIを活かせないか」「この作業、自動化できないか」——
そんな漠然とした段階からで大丈夫です。大阪のAI・システム開発会社VISKが、御社の課題に合わせて、企画から開発・検証までサポートします。
