「AIが画面の全ピクセルを描く」って本当?話題のFlipbookを実測してみた
「AIが画面の全ピクセルを描く」って本当?話題のFlipbookを実測してみた

はじめに:ある日X(Twitter)で見かけた投稿
「HTMLもコードも一切いらない。AIが画面の全ピクセルを直接生成してストリーミングする時代が来た!UI/UXの常識を180度変える未来のテクノロジー!」
なんやそれ。気になって調べてみると、これFlipbookっていうプロトタイプの話やった。元OpenAI研究者のZain Shahらが作って、flipbook.page で公開中。HTMLもCSSも使わず、AIが画面の絵を毎回ゼロから生成して、WebSocket経由でブラウザに送ってくる、という仕組みらしい。
ほんまにそんなすごいモンか?投稿の内容を鵜呑みにする前に、自分で触って確かめました。
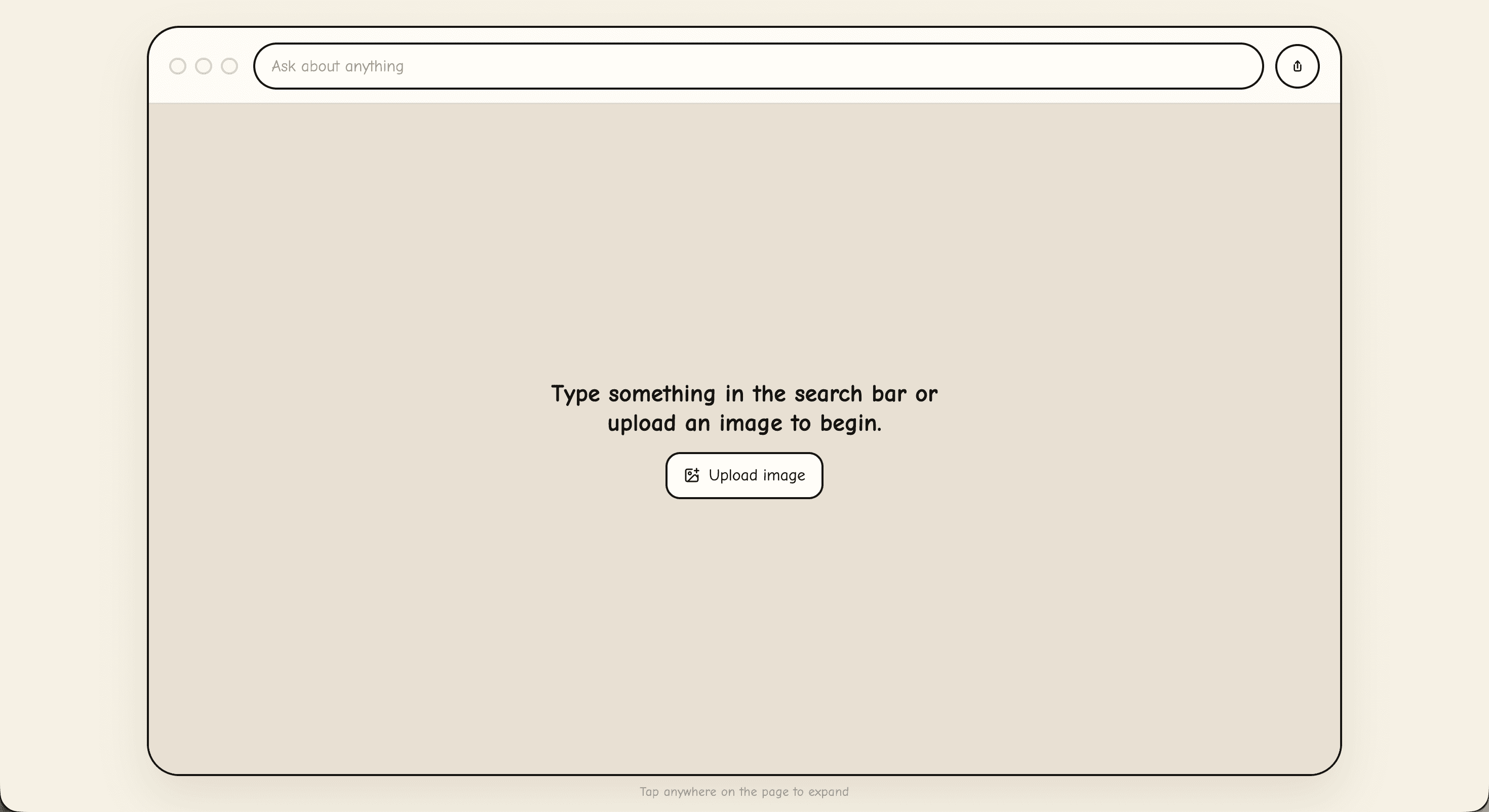
アクセスして最初に出てくる画面がコレ。ベージュ色の背景に、手描き風のブラウザ枠と検索バー。フォントも丸っこくてどこか温かみのある雰囲気で、**普通のWebサイトとは明らかに違う「絵本っぽい世界観」**になってる。これだけで「お、なんか可愛いやん」ってちょっと期待値が上がる。
まず仕組みのおさらい
技術的な背景だけ先にサクッと:
画像生成モデル:イスラエルLightricks社の LTX Studio(オープンソースのDiT動画生成モデル)
バックエンド:Modal Labsのサーバーレス GPU
配信:WebSocketで1080p・24fpsのライブストリーミング
つまり、動画生成モデルを「ブラウザの代替」として使ってるっていう発想です。Geminiやないで。投稿には「Geminiを活用」って書いてあったけど、ここは事実と違う。
検証①:とりあえずローマ帝国を聞いてみた
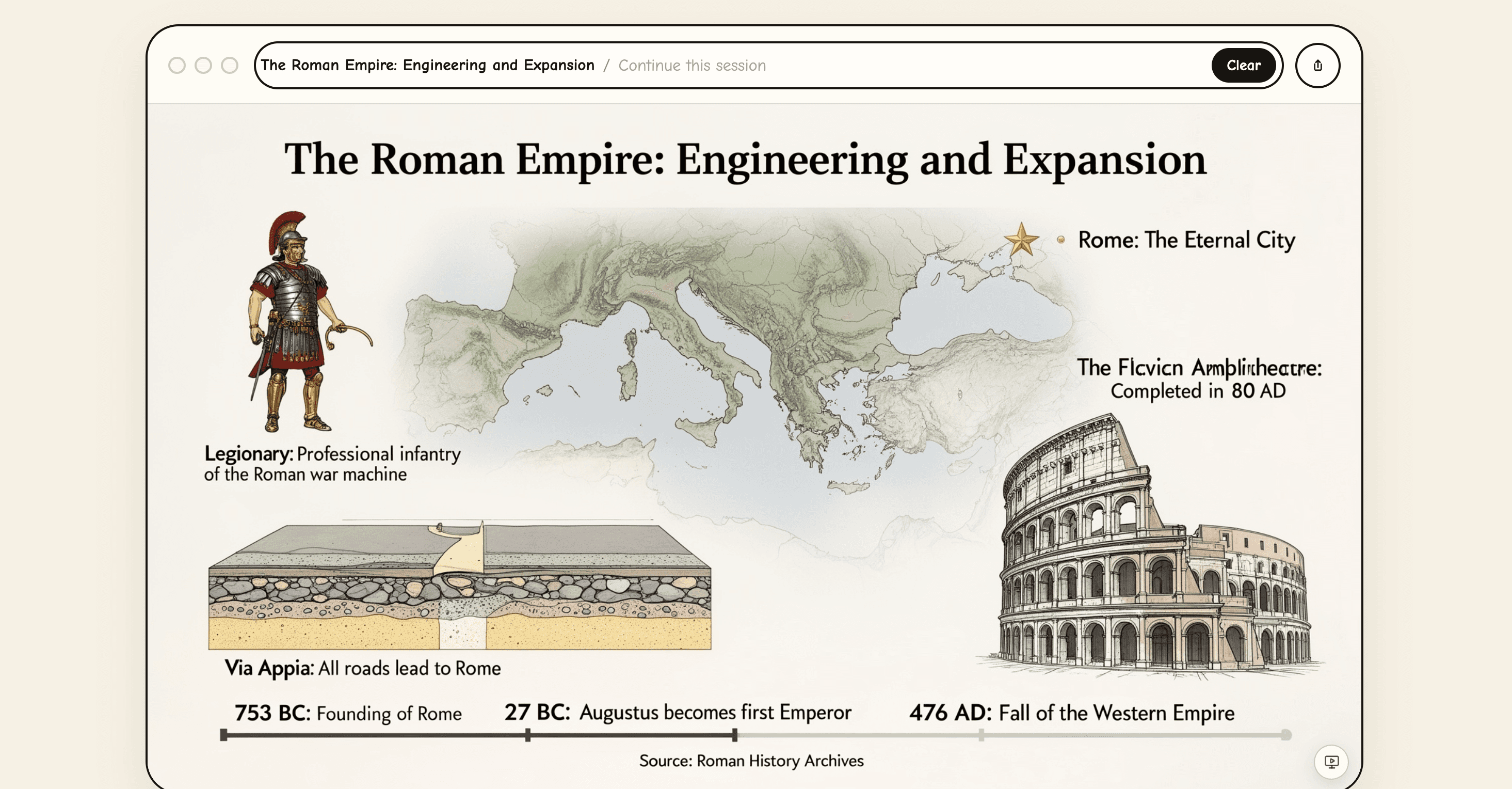
第一印象、思ったよりキレイ。地中海の地図、コロッセオ、軍団兵、アッピア街道の断面図、年表。教科書か博物館の解説パネルみたいなレイアウトで出てきた。
ただし、よく見ると文字が崩れてる。「Flavian Amphitheatre」が「Flcvicn Amphlrlhectre」っていう、誰も読めん古代文字みたいになってる。これは画像生成モデルの典型的な弱点で、文字を「文字」として扱わず、「文字っぽい絵」として描いてるから起こる現象。
検証②:「日本語いける?」って聞いたら、英語より読めた件

英語版で文字化けしてたから、半信半疑で検索バーに「日本語いける?」って聞いてみた。すると次に「pizza」と入力したら、完全に日本語のインフォグラフィックが出てきた。
しかも内容が正確。
「コルニチョーネ:空気をたっぷり含んだ縁の部分」← ✅
「サンマルツァーノトマト:ヴェスヴィオ火山麓の肥沃な土壌で育つ」← ✅
「485℃の薪窯で60〜90秒焼成」← ✅(ナポリピッツァ協会の規格通り)
ローマ帝国で「Flcvicn」になってた英語より、漢字とカタカナの方がキレイに描画されるっていう逆転現象。LTX Studioの学習データに日本語コンテンツが意外と入ってるってことかも。
検証③:クリック深掘りの精度
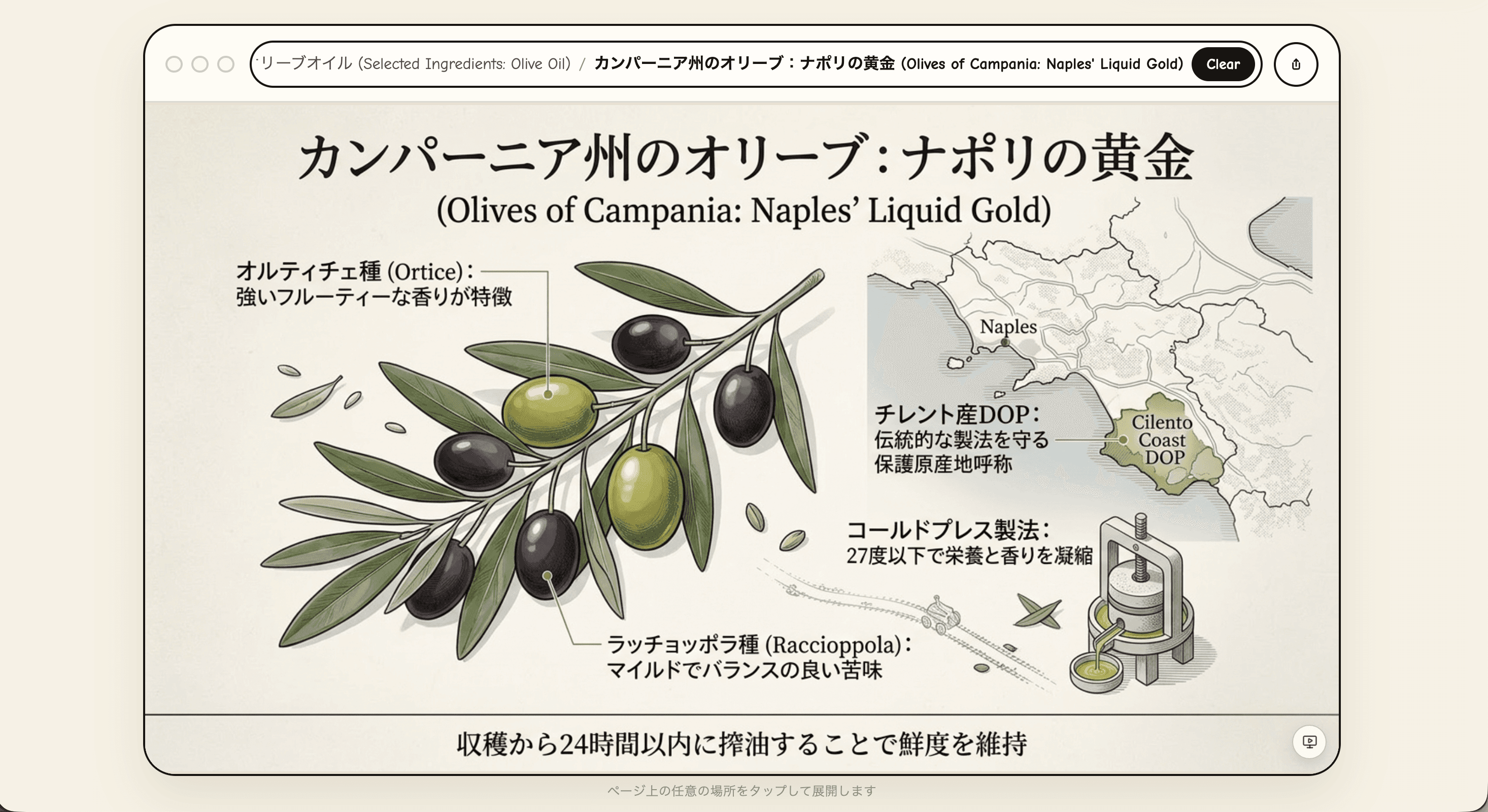
オイル差しの絵をクリックしたら「ナポリピッツァの厳選素材:オリーブオイル」のページに遷移。さらにオリーブの実をクリックしたら「カンパーニア州のオリーブ:ナポリの黄金」へ。
挙動としては:
✅ クリックした絵と、次に出るページの関連性は正確
✅ 「Cilento Coast DOP」「コールドプレス27度以下」など、専門知識も正しい
⚠️ ただしページごとに文字の品質が大きく揺れる(オリーブオイルのページは「ナポリピーーソツォ」と崩壊、カンパーニア州のページは超キレイ)
クリックの精度は思ったより高い。ただ「画像のどこでもインタラクティブ」っていう謳い文句は、実態は「主要オブジェクトをクリックすると関連ページに飛ぶ」程度で、Webリンクと体験的にはあんまり変わらん印象。
検証④:日本のローカル知識はどこまで対応?
「石垣島」で試してみた。
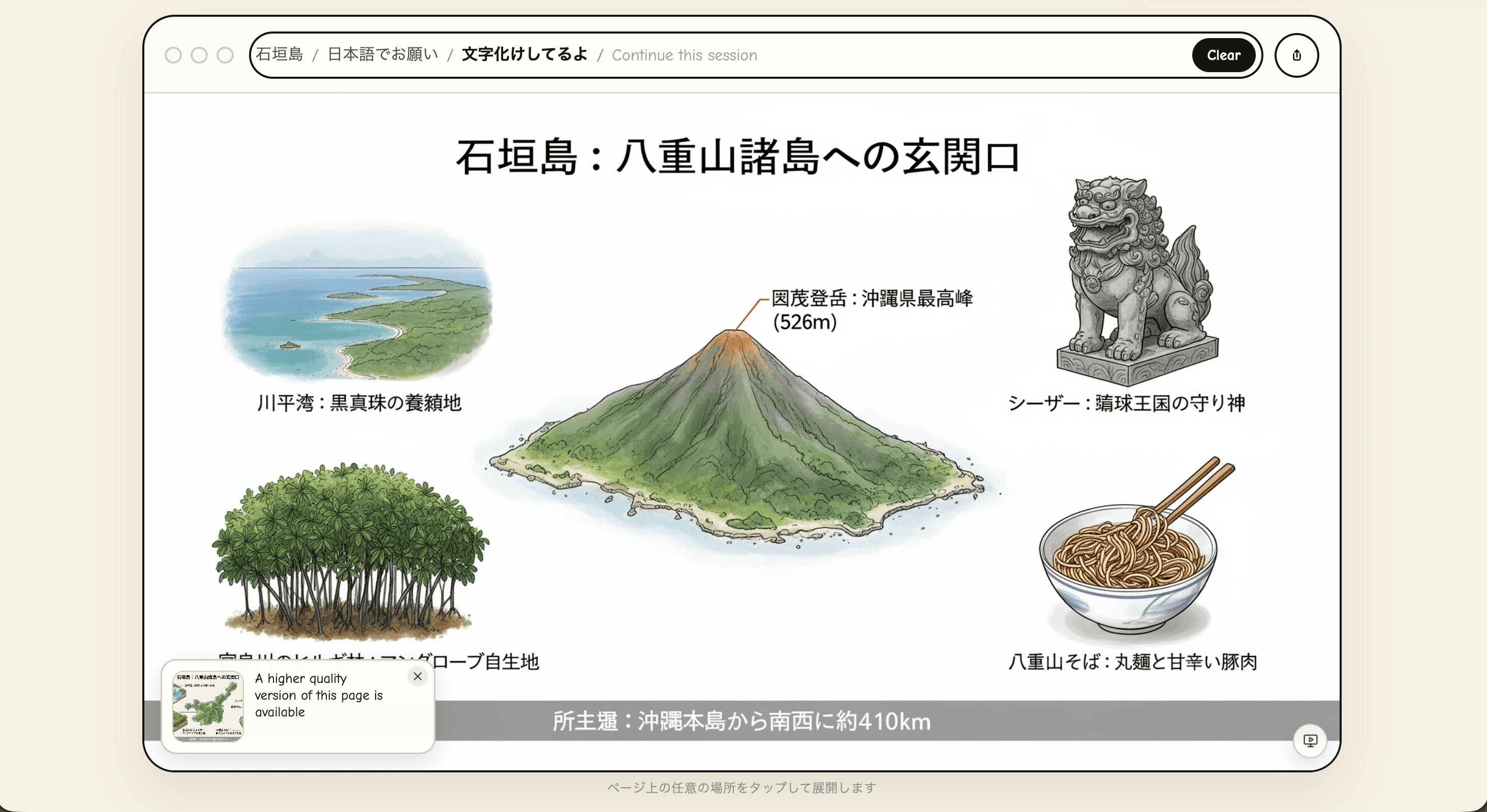
地元民じゃないと知らんレベルの情報まで意外と正確:
沖縄県最高峰「於茂登岳」の標高 525m ← ✅
川平湾は黒蝶真珠の養殖地 ← ✅
八重山そば(丸麺と豚肉) ← ✅
沖縄本島から南西に約410km ← ✅
ただし漢字が崩れる:
「於茂登岳」→「囡茂登岳」
「琉球王国」→「靖球王国」
LLMの知識ベース(Wikipedia等)は地方情報も結構網羅してるけど、画像生成モデル側で漢字を絵として描く段階で崩れるっていう、Flipbook特有の構造的な問題が見えてくる。
検証⑤:「文字化けしてるよ」と注意してみた
検索バーに「文字化けしてるよ」と打ってみた。完全に直りはしなかったけど、メインのタイトルや見出しは前より丁寧に描こうとしてる痕跡は見えた。
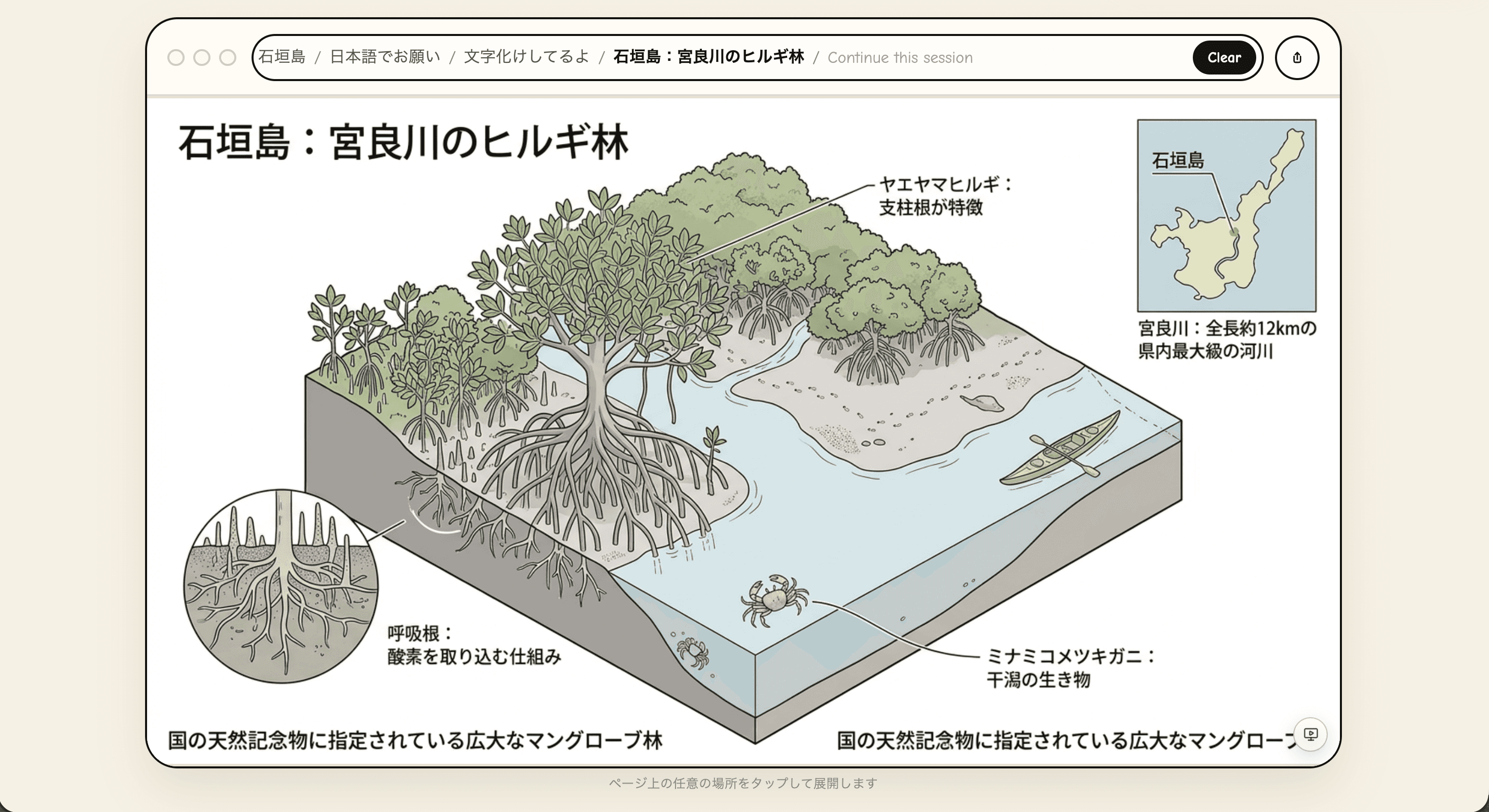
「石垣島:宮良川のヒルギ林」っていう次のページでは、漢字の難しいやつ(呼吸根、宮良川、天然記念物)も全部正確。フィードバックは部分的に反映されてる。
つまりFlipbookの挙動は「意図は汲み取るけど、画像生成モデル側のコントロール限界がある」が正しい表現。完全無視ではない。
検証⑥【最大の発見】:実は2段階で生成してる、その正体

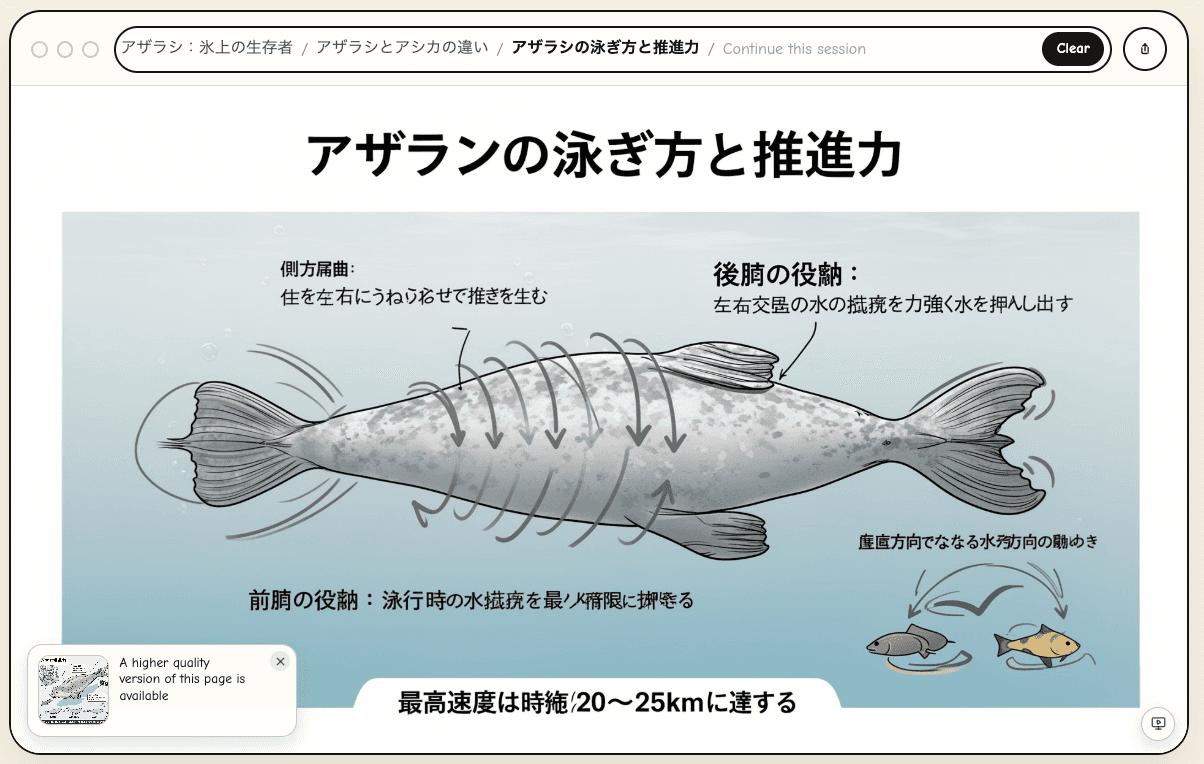
動物でも試してみた。
「アザラシ」で検索してクリックを進めていくと、最初に出てきた絵がコレ。
よく見ると、アザラシの下半身ともう1匹のアザラシの下半身が逆向きに合体してる
つまり**逆双頭の合成生物「アザラン」**が爆誕してる。タイトルも「アザランの泳ぎ方と推進力」になってて、もはやAIが新種を発明してる。
ところが、画面の左下に「A higher quality version of this page is available(高品質版が利用可能)」というポップアップが出る。それをクリックしてみると…

ちゃんとしたアザラシが出てきた。
体型も正確
「脊椎の柔軟性:体をS字に曲げて」「後肢を左右に振って推進」など解説も完璧
右下には「アシカとの違い:前肢を翼のように羽ばたかせて泳ぐ」という比較情報まで
つまりFlipbookの「爆速」の正体は:
クリック直後:低品質モデルで即座に表示(速さ優先、構図が破綻することも)
裏側で並行処理:高品質版を生成
完成すると:「higher quality available」のポップアップ表示
ユーザーがクリック:高品質版に差し替え
「速い」のは、最初に低品質版を見せてるからやった。Nano Banana(Gemini 2.5 Flash Image)が遅く感じるのは、1枚を完璧に仕上げてから出すから。UXの設計思想が逆なんですわ。
検証⑦:人気キャラものを試したら、細部がちょいちょい怪しい
著作権配慮でキャラ名は伏せて、スクショもモザイク処理した上で紹介します。
帽子がトレードマークの世界的ゲームキャラ
ゲームの歴史はちゃんと教えてくれた。ただ、よく見ると気になる点が。
相棒の緑の恐竜キャラ、普段履いている赤い靴を脱いで裸足になってた。貴重な足を見ることができました。
動物と島作りをするゲーム

こちらは内容自体はちゃんと生成してくれた。ゲームの雰囲気がしっかり伝わる絵が出てきた。
1998年発売のJRPG(90年代後半の名作RPG)

✅ ストーリーや設定の文章は概ね正確(誤字はあるけど内容は合ってる)
❌ 画像は公式と全く別物のイラスト(文字ぼかしだけで済んだから助かった)
文章は合ってるのに絵が別物。これってどういうこと?
この差から見えてくる「LLMの知識 ≠ 画像生成の知識」問題
3つの検証から見えてきた構造的な弱点を整理すると:
LLMの「テキスト知識」
Wikipedia、ファンサイト、レビュー記事など文字情報は20年以上前のタイトルもカバー
だから「1998年発売」「ストーリー概要」「キャラ設定」は文章で正確に出せる
画像生成モデルの「ビジュアル知識」
学習データは現代の3D・実写・アニメ調が圧倒的多数
1990年代の2Dドット絵はネットへの流通量が少なく、学習データも薄い
結果:「文章では知ってる」のに正しい絵が描けない
つまりFlipbookは、LLMと画像生成モデルという別々の脳を組み合わせてる。片方だけ強くてもダメで、特に古いゲームキャラ・特定IPの細部になると、両者の知識量のギャップが露呈する。
まとめ:投稿の答え合わせ
最初の投稿の主張をひとつずつ検証した結果:
主張 | 実態 |
|---|---|
AIが画面の全ピクセルを生成 | ✅ その通り |
HTMLもコードも不要 | ✅ その通り(WebSocket経由) |
ブラウザのレイアウトエンジン不使用 | ✅ その通り |
Geminiなど最新AIモデルを活用 | ❌ 実際はLightricks社のLTX Studio |
超高速な描画 | △ 低品質版を先に出してるトリック |
プロトタイプ制作が爆速化 | ⚠️ 現状は「視覚的な百科事典」の域 |
ユーザーごとに最適なUIを発明 | ⚠️ 現時点では実現してない |
UI/UXの常識を180度変える | ⚠️ 表現として盛り気味 |
コンセプト自体は正確に紹介されてる。ただし使われてるモデル名の誤りや、未来の可能性を現在形で書いてる部分はある。
ほなFlipbookって何やったら使える?
検証してみて思ったのは、**「タッチペン絵本の上位互換」**っていう位置付けが一番しっくりくる、ということ。
ほら、子供の頃あったやないですか。ペンで絵本のページに触れると、絵の説明や音声が出てくる教材。あれって:
絵は印刷済み(固定)
触れる場所も決まってる
反応も録音済み
これに対してFlipbookは:
絵は毎回その場で生成
触れる場所は画像のどこでも
反応は新しい絵と情報がその場で生まれる
教材メーカーが何百人がかりで作ってたコンテンツを、AIが質問のたびに即興で代替してる構造。だから:
✅ 未就学児や文字を読めない人が世界の知識に触れる入口として優秀
✅ 言語の壁を超える視覚情報伝達として有望
❌ 学習教材としては検証なしには危険(「於茂登岳」が「囡茂登岳」になる)
❌ 業務ツールや実用UIには程遠い
「Wikipediaのビジュアル版」「子供向け図鑑のAI版」っていうカテゴリの第一歩として見ると、確かに新しい。でも「UI/UXの常識を180度変える」みたいな大風呂敷を信じて投資したらヤケドします。
進化したらめっちゃ可能性ある
今回の検証で見えた弱点をひとつずつ思い返すと:
文字描画が崩れる
細部の固定属性が再現できない(裸足の恐竜キャラ問題)
構図が破綻する(アザラン誕生)
古いコンテンツの画像精度が低い
これら全部、画像生成モデルの精度が上がれば自動的に解決される問題ばかり。LTX Studioもまだ若いモデルやし、今後数ヶ月〜数年で品質が上がるのは確実。
そう考えると、Flipbookは「現時点」じゃなくて「将来性」で評価すべきツールやと思う。今は「アザラン爆誕」みたいなネタで笑えるレベルやけど、画像生成の精度が今の3倍くらいになったら:
子供向けの動的な図鑑アプリとして実用レベルになる
言語の壁を超える観光案内ツールになりうる
視覚優位で学ぶ人にとっての新しい知識インターフェースになる
「チャットボックスにテキスト打つだけのAI体験」とは違う方向性で進化してるのは確か。今後のアップデートを楽しみに、たまに様子見しに行きたいツールですね。
結論:触ってみんとわからん
紹介記事を読んで「すごい!」って思考停止するんじゃなくて、自分で触って確かめる。今回もそれが正解やった。
ビジネス層にAIツールを紹介するときは、煽り文句や紹介記事の表現を鵜呑みにせず、実測データで語ることが大事ですね。
ほな、また何か話題のツール出てきたら検証していきます。
検証日:2026年4月30日〜5月1日
検証ツール:Flipbook(flipbook.page)
所要時間:約1時間
はじめに:ある日X(Twitter)で見かけた投稿
「HTMLもコードも一切いらない。AIが画面の全ピクセルを直接生成してストリーミングする時代が来た!UI/UXの常識を180度変える未来のテクノロジー!」
なんやそれ。気になって調べてみると、これFlipbookっていうプロトタイプの話やった。元OpenAI研究者のZain Shahらが作って、flipbook.page で公開中。HTMLもCSSも使わず、AIが画面の絵を毎回ゼロから生成して、WebSocket経由でブラウザに送ってくる、という仕組みらしい。
ほんまにそんなすごいモンか?投稿の内容を鵜呑みにする前に、自分で触って確かめました。
アクセスして最初に出てくる画面がコレ。ベージュ色の背景に、手描き風のブラウザ枠と検索バー。フォントも丸っこくてどこか温かみのある雰囲気で、**普通のWebサイトとは明らかに違う「絵本っぽい世界観」**になってる。これだけで「お、なんか可愛いやん」ってちょっと期待値が上がる。
まず仕組みのおさらい
技術的な背景だけ先にサクッと:
画像生成モデル:イスラエルLightricks社の LTX Studio(オープンソースのDiT動画生成モデル)
バックエンド:Modal Labsのサーバーレス GPU
配信:WebSocketで1080p・24fpsのライブストリーミング
つまり、動画生成モデルを「ブラウザの代替」として使ってるっていう発想です。Geminiやないで。投稿には「Geminiを活用」って書いてあったけど、ここは事実と違う。
検証①:とりあえずローマ帝国を聞いてみた
第一印象、思ったよりキレイ。地中海の地図、コロッセオ、軍団兵、アッピア街道の断面図、年表。教科書か博物館の解説パネルみたいなレイアウトで出てきた。
ただし、よく見ると文字が崩れてる。「Flavian Amphitheatre」が「Flcvicn Amphlrlhectre」っていう、誰も読めん古代文字みたいになってる。これは画像生成モデルの典型的な弱点で、文字を「文字」として扱わず、「文字っぽい絵」として描いてるから起こる現象。
検証②:「日本語いける?」って聞いたら、英語より読めた件
英語版で文字化けしてたから、半信半疑で検索バーに「日本語いける?」って聞いてみた。すると次に「pizza」と入力したら、完全に日本語のインフォグラフィックが出てきた。
しかも内容が正確。
「コルニチョーネ:空気をたっぷり含んだ縁の部分」← ✅
「サンマルツァーノトマト:ヴェスヴィオ火山麓の肥沃な土壌で育つ」← ✅
「485℃の薪窯で60〜90秒焼成」← ✅(ナポリピッツァ協会の規格通り)
ローマ帝国で「Flcvicn」になってた英語より、漢字とカタカナの方がキレイに描画されるっていう逆転現象。LTX Studioの学習データに日本語コンテンツが意外と入ってるってことかも。
検証③:クリック深掘りの精度
オイル差しの絵をクリックしたら「ナポリピッツァの厳選素材:オリーブオイル」のページに遷移。さらにオリーブの実をクリックしたら「カンパーニア州のオリーブ:ナポリの黄金」へ。
挙動としては:
✅ クリックした絵と、次に出るページの関連性は正確
✅ 「Cilento Coast DOP」「コールドプレス27度以下」など、専門知識も正しい
⚠️ ただしページごとに文字の品質が大きく揺れる(オリーブオイルのページは「ナポリピーーソツォ」と崩壊、カンパーニア州のページは超キレイ)
クリックの精度は思ったより高い。ただ「画像のどこでもインタラクティブ」っていう謳い文句は、実態は「主要オブジェクトをクリックすると関連ページに飛ぶ」程度で、Webリンクと体験的にはあんまり変わらん印象。
検証④:日本のローカル知識はどこまで対応?
「石垣島」で試してみた。
地元民じゃないと知らんレベルの情報まで意外と正確:
沖縄県最高峰「於茂登岳」の標高 525m ← ✅
川平湾は黒蝶真珠の養殖地 ← ✅
八重山そば(丸麺と豚肉) ← ✅
沖縄本島から南西に約410km ← ✅
ただし漢字が崩れる:
「於茂登岳」→「囡茂登岳」
「琉球王国」→「靖球王国」
LLMの知識ベース(Wikipedia等)は地方情報も結構網羅してるけど、画像生成モデル側で漢字を絵として描く段階で崩れるっていう、Flipbook特有の構造的な問題が見えてくる。
検証⑤:「文字化けしてるよ」と注意してみた
検索バーに「文字化けしてるよ」と打ってみた。完全に直りはしなかったけど、メインのタイトルや見出しは前より丁寧に描こうとしてる痕跡は見えた。
「石垣島:宮良川のヒルギ林」っていう次のページでは、漢字の難しいやつ(呼吸根、宮良川、天然記念物)も全部正確。フィードバックは部分的に反映されてる。
つまりFlipbookの挙動は「意図は汲み取るけど、画像生成モデル側のコントロール限界がある」が正しい表現。完全無視ではない。
検証⑥【最大の発見】:実は2段階で生成してる、その正体
動物でも試してみた。
「アザラシ」で検索してクリックを進めていくと、最初に出てきた絵がコレ。
よく見ると、アザラシの下半身ともう1匹のアザラシの下半身が逆向きに合体してる
つまり**逆双頭の合成生物「アザラン」**が爆誕してる。タイトルも「アザランの泳ぎ方と推進力」になってて、もはやAIが新種を発明してる。
ところが、画面の左下に「A higher quality version of this page is available(高品質版が利用可能)」というポップアップが出る。それをクリックしてみると…
ちゃんとしたアザラシが出てきた。
体型も正確
「脊椎の柔軟性:体をS字に曲げて」「後肢を左右に振って推進」など解説も完璧
右下には「アシカとの違い:前肢を翼のように羽ばたかせて泳ぐ」という比較情報まで
つまりFlipbookの「爆速」の正体は:
クリック直後:低品質モデルで即座に表示(速さ優先、構図が破綻することも)
裏側で並行処理:高品質版を生成
完成すると:「higher quality available」のポップアップ表示
ユーザーがクリック:高品質版に差し替え
「速い」のは、最初に低品質版を見せてるからやった。Nano Banana(Gemini 2.5 Flash Image)が遅く感じるのは、1枚を完璧に仕上げてから出すから。UXの設計思想が逆なんですわ。
検証⑦:人気キャラものを試したら、細部がちょいちょい怪しい
著作権配慮でキャラ名は伏せて、スクショもモザイク処理した上で紹介します。
帽子がトレードマークの世界的ゲームキャラ
ゲームの歴史はちゃんと教えてくれた。ただ、よく見ると気になる点が。
相棒の緑の恐竜キャラ、普段履いている赤い靴を脱いで裸足になってた。貴重な足を見ることができました。
動物と島作りをするゲーム
こちらは内容自体はちゃんと生成してくれた。ゲームの雰囲気がしっかり伝わる絵が出てきた。
1998年発売のJRPG(90年代後半の名作RPG)
✅ ストーリーや設定の文章は概ね正確(誤字はあるけど内容は合ってる)
❌ 画像は公式と全く別物のイラスト(文字ぼかしだけで済んだから助かった)
文章は合ってるのに絵が別物。これってどういうこと?
この差から見えてくる「LLMの知識 ≠ 画像生成の知識」問題
3つの検証から見えてきた構造的な弱点を整理すると:
LLMの「テキスト知識」
Wikipedia、ファンサイト、レビュー記事など文字情報は20年以上前のタイトルもカバー
だから「1998年発売」「ストーリー概要」「キャラ設定」は文章で正確に出せる
画像生成モデルの「ビジュアル知識」
学習データは現代の3D・実写・アニメ調が圧倒的多数
1990年代の2Dドット絵はネットへの流通量が少なく、学習データも薄い
結果:「文章では知ってる」のに正しい絵が描けない
つまりFlipbookは、LLMと画像生成モデルという別々の脳を組み合わせてる。片方だけ強くてもダメで、特に古いゲームキャラ・特定IPの細部になると、両者の知識量のギャップが露呈する。
まとめ:投稿の答え合わせ
最初の投稿の主張をひとつずつ検証した結果:
主張 | 実態 |
|---|---|
AIが画面の全ピクセルを生成 | ✅ その通り |
HTMLもコードも不要 | ✅ その通り(WebSocket経由) |
ブラウザのレイアウトエンジン不使用 | ✅ その通り |
Geminiなど最新AIモデルを活用 | ❌ 実際はLightricks社のLTX Studio |
超高速な描画 | △ 低品質版を先に出してるトリック |
プロトタイプ制作が爆速化 | ⚠️ 現状は「視覚的な百科事典」の域 |
ユーザーごとに最適なUIを発明 | ⚠️ 現時点では実現してない |
UI/UXの常識を180度変える | ⚠️ 表現として盛り気味 |
コンセプト自体は正確に紹介されてる。ただし使われてるモデル名の誤りや、未来の可能性を現在形で書いてる部分はある。
ほなFlipbookって何やったら使える?
検証してみて思ったのは、**「タッチペン絵本の上位互換」**っていう位置付けが一番しっくりくる、ということ。
ほら、子供の頃あったやないですか。ペンで絵本のページに触れると、絵の説明や音声が出てくる教材。あれって:
絵は印刷済み(固定)
触れる場所も決まってる
反応も録音済み
これに対してFlipbookは:
絵は毎回その場で生成
触れる場所は画像のどこでも
反応は新しい絵と情報がその場で生まれる
教材メーカーが何百人がかりで作ってたコンテンツを、AIが質問のたびに即興で代替してる構造。だから:
✅ 未就学児や文字を読めない人が世界の知識に触れる入口として優秀
✅ 言語の壁を超える視覚情報伝達として有望
❌ 学習教材としては検証なしには危険(「於茂登岳」が「囡茂登岳」になる)
❌ 業務ツールや実用UIには程遠い
「Wikipediaのビジュアル版」「子供向け図鑑のAI版」っていうカテゴリの第一歩として見ると、確かに新しい。でも「UI/UXの常識を180度変える」みたいな大風呂敷を信じて投資したらヤケドします。
進化したらめっちゃ可能性ある
今回の検証で見えた弱点をひとつずつ思い返すと:
文字描画が崩れる
細部の固定属性が再現できない(裸足の恐竜キャラ問題)
構図が破綻する(アザラン誕生)
古いコンテンツの画像精度が低い
これら全部、画像生成モデルの精度が上がれば自動的に解決される問題ばかり。LTX Studioもまだ若いモデルやし、今後数ヶ月〜数年で品質が上がるのは確実。
そう考えると、Flipbookは「現時点」じゃなくて「将来性」で評価すべきツールやと思う。今は「アザラン爆誕」みたいなネタで笑えるレベルやけど、画像生成の精度が今の3倍くらいになったら:
子供向けの動的な図鑑アプリとして実用レベルになる
言語の壁を超える観光案内ツールになりうる
視覚優位で学ぶ人にとっての新しい知識インターフェースになる
「チャットボックスにテキスト打つだけのAI体験」とは違う方向性で進化してるのは確か。今後のアップデートを楽しみに、たまに様子見しに行きたいツールですね。
結論:触ってみんとわからん
紹介記事を読んで「すごい!」って思考停止するんじゃなくて、自分で触って確かめる。今回もそれが正解やった。
ビジネス層にAIツールを紹介するときは、煽り文句や紹介記事の表現を鵜呑みにせず、実測データで語ることが大事ですね。
ほな、また何か話題のツール出てきたら検証していきます。
検証日:2026年4月30日〜5月1日
検証ツール:Flipbook(flipbook.page)
所要時間:約1時間

AI・システム開発のこと、VISKにご相談ください
「自社の業務にAIを活かせないか」「この作業、自動化できないか」——
そんな漠然とした段階からで大丈夫です。大阪のAI・システム開発会社VISKが、御社の課題に合わせて、企画から開発・検証までサポートします。
