Tencent WeKnora を Gemini で動かしたら、embedding で2回ハマった話 ―― 404とtruncate_prompt_tokens、そしてローカルOllamaでの回避
Tencent WeKnora を Gemini で動かしたら、embedding で2回ハマった話 ―― 404とtruncate_prompt_tokens、そしてローカルOllamaでの回避

Tencent WeKnora を Gemini で動かしたら、embedding で2回ハマった話 ―― 404とtruncate_prompt_tokens、そしてローカルOllamaでの回避
Tencent が公開しているOSSのナレッジ基盤「WeKnora」を、社内文書RAGの検証用に手元の Mac で動かしてみました。
セットアップ自体はサクサク進んだのですが、「埋め込み(embedding)に Gemini を使う」ところで立て続けにつまずきました。原因にたどり着くまでにけっこう寄り道したので、その過程をそのまま残しておきます。同じ構成で同じところに引っかかる人がいたら、参考になればと思います。気軽に読んでもらえたら。
なお、ここに書いた内容はすべて検証時点で手元で再現したものです。WeKnora は更新が速いので、仕様が変わっていそうなところは都度ことわりを入れています。
検証した環境
マシン:Apple Silicon の Mac / メモリ 8GB
動かし方:Docker Compose(コア構成だけ。Neo4j や Langfuse まで入れるフル構成は、メモリの都合で今回は見送り)
WeKnora:検証時点の
:latestイメージ(途中で v0.6.1 に更新)最初に使おうとしたモデル
埋め込み:
gemini-embedding-001(Gemini API の OpenAI 互換エンドポイント経由)LLM:
gemini-2.5-flash
メモリ 8GB ということもあって、最初は「LLM も埋め込みも全部クラウド(Gemini)に任せよう」と考えていました。……が、この方針が後々の伏線になります。
つまずき①:embedding が 404 になる(犯人は末尾の /)
どうなったか
文書をアップロードすると、ステータスが 「Parsing failed」。あっさり失敗しました。
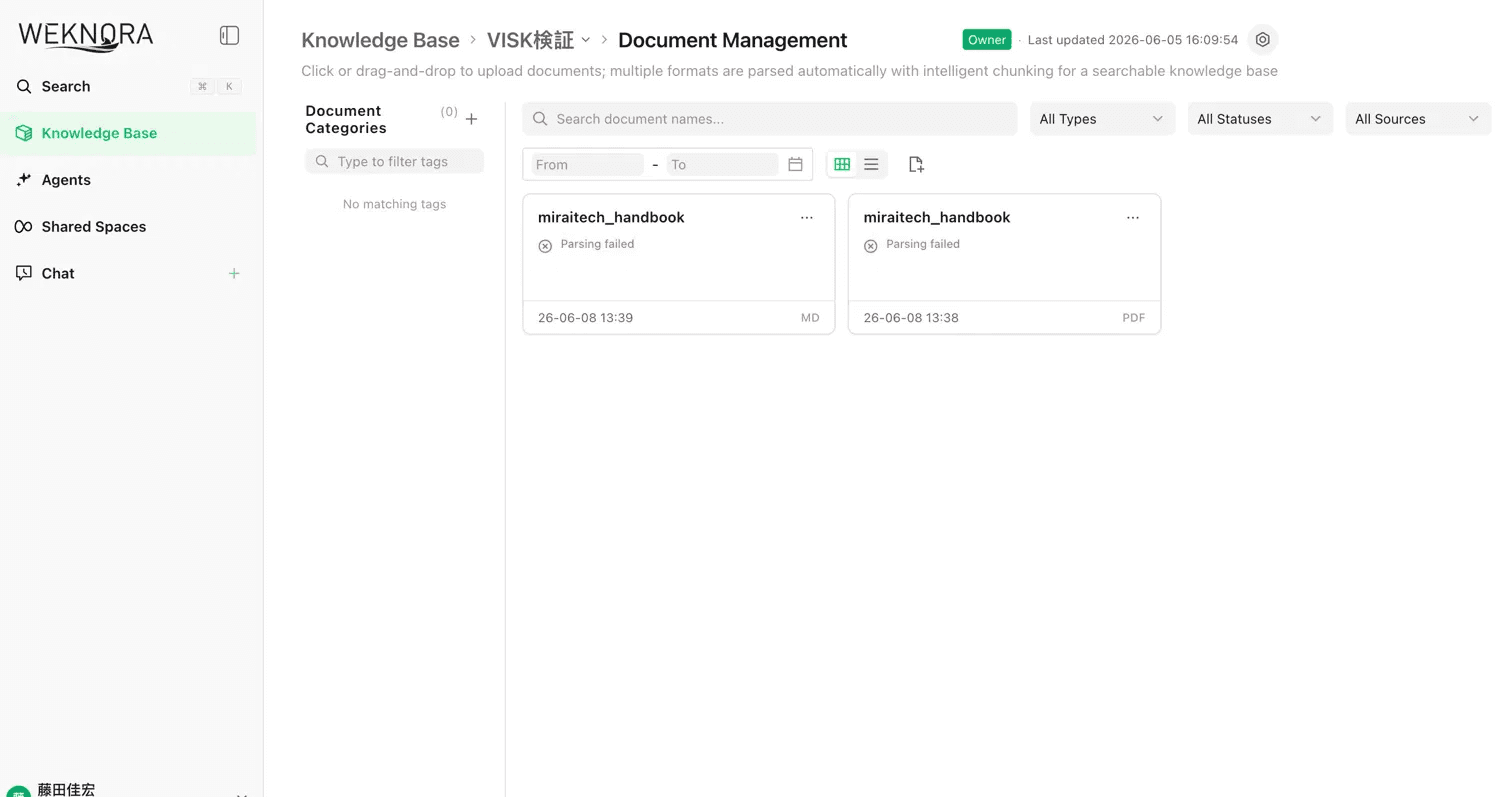
▲ アップロードした文書が軒並み「Parsing failed」。ここから原因の切り分けが始まりました
原因をどう絞ったか
まずは「解析(テキストを読み取る段階)」と「埋め込み(ベクトル化する段階)」のどっちでコケているのか、を切り分けました。
解析を担当する docreader のログを見ると、PDF も Markdown もテキスト抽出はちゃんと成功しています。
ということは、コケているのはその次の段階、app 側(チャンク分割と埋め込み)です。app のログを見たら、原因がはっきり書いてありました。
なぜ404だったか、どう直したか
404 は「そのURL、存在しませんよ」というサイン。Gemini の OpenAI 互換エンドポイントで embedding を叩くこと自体はできる(curl で直接叩くとちゃんと届く)のに、なぜか404。
犯人は、WeKnora に設定した Base URL の末尾に付けていた / でした。
設定していた値(NG):
https://generativelanguage.googleapis.com/v1beta/openai/直したあと(OK):
https://generativelanguage.googleapis.com/v1beta/openai
末尾スラッシュを外したら、エラーが 404 から 400 に変わりました。「URLが見つからない」状態は抜けて、リクエストがエンドポイントまで届くようになった、ということです。
ちょっと補足(ここは推測です):末尾に
/があると、WeKnora がURLを組み立てるときに.../openai//embeddingsのようにスラッシュが二重になって 404 になっていたのかな、と思っています。内部の挙動までは追っていないので推測どまりですが、「末尾スラッシュを外したら404が消えた」のは事実です。
つまずき②:今度は truncate_prompt_tokens で 400
どうなったか
404 は消えたのに、入れ替わりで今度はこれが出るように。
EmbedBatch API error: Http Status 400 Bad Request "Invalid JSON payload received. Unknown name \"truncate_prompt_tokens\"
なぜ起きるか
WeKnora の埋め込み処理が、リクエストに truncate_prompt_tokens というフィールドを乗せて送っていて、Gemini 側が「そんなフィールド知らない」とリクエストごと突き返していた、というのが原因です。
調べてみたら、これは WeKnora 側の既知の不具合で、リリースノートにこんな修正が載っていました。
fix(embedding): remove hardcoded TruncatePromptTokens in BatchEmbed
「BatchEmbed にハードコードされていた TruncatePromptTokens を取り除く」という修正です。コードに直接埋め込まれていた値なので、設定画面から無効化する、という逃げ方はできませんでした。
修正版に上げようとしたものの……
直っているはずの新しい版に上げようと、本体を更新しました。
git pull docker compose pull docker compose up -d
ソースは v0.6.1 まで上がったのですが、docker compose pull で取ってきた :latest イメージにはまだ修正が入っておらず、同じ 400 がそのまま再発しました。ここはちょっと拍子抜けでした。
補足(推測):公開イメージがソースの修正に追いついていなかったか、修正が当該タグにまだ含まれていなかったか、のどちらかだと思います。そこまでは確認できていません。確実なのは「更新後も
:latestでは同じエラーが出た」という結果だけです。ソースから自前でビルドする方法は、今回は試していません。
抜け道:埋め込みだけ、ローカルの Ollama に逃がす
Gemini 経由の埋め込みがバグで止まってしまうので、思い切って埋め込みだけをローカルの Ollama に切り替え、LLM はクラウドの Gemini のまま残すことにしました。埋め込みモデルは LLM に比べてずっと軽いので、メモリ 8GB でも「埋め込みだけなら」十分動かせる、という読みです。
やったことの要点
Ollama を入れる(Homebrew 版はインストールでつまずきました。
llama-serverのバイナリが見つからず推論できなかったので、公式アプリ版に切り替え)日本語に強い埋め込みモデルを取得
WeKnora に Ollama 埋め込みモデルを登録
Source:Ollama (Local)
Model:
bge-m3Vector Dimension:
1024
既存のナレッジベースは旧モデルで作っていたので、埋め込みを
bge-m3にして作り直し
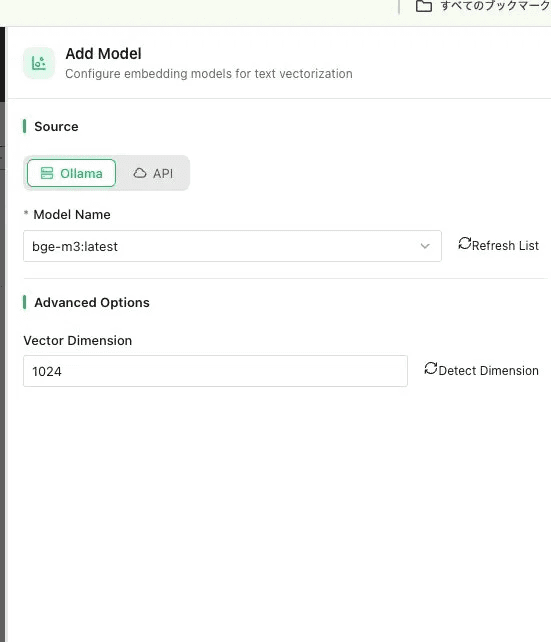
▲ Source を「Ollama (Local)」にして bge-m3 を登録。次元は 1024
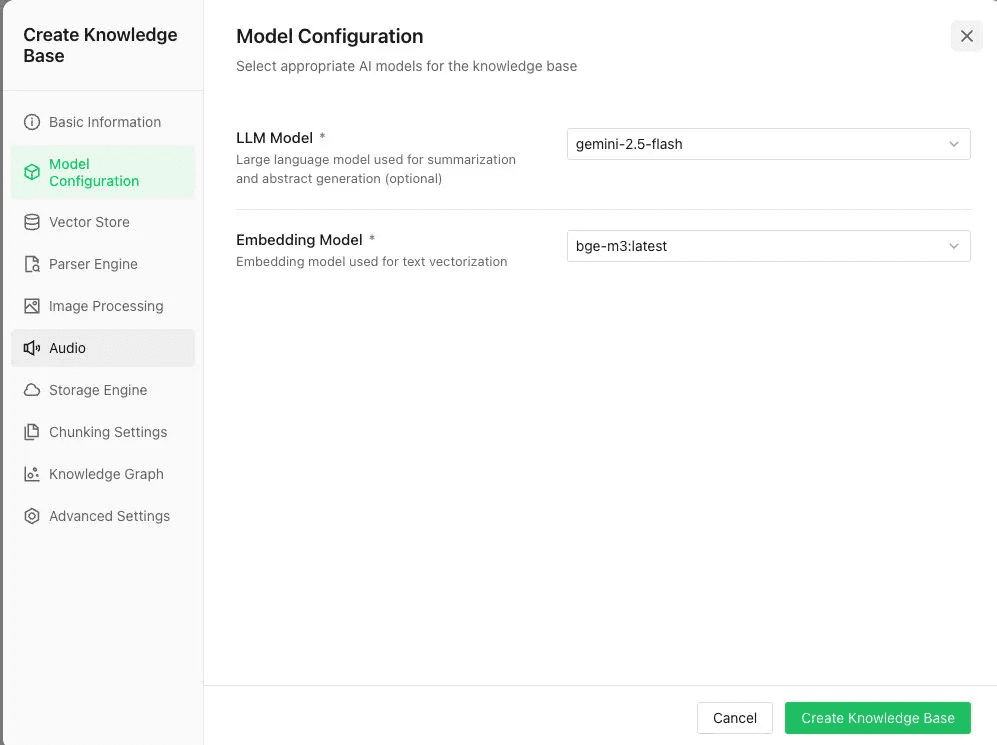
▲ ナレッジベースを作り直し、埋め込みに bge-m3、LLM に gemini-2.5-flash を指定
Docker からホストの Ollama に繋ぐときの小さな罠
WeKnora は Docker コンテナの中で動いているので、コンテナから見た localhost は「コンテナ自身」を指してしまいます。ホストの Mac で動いている Ollama に繋ぐには、localhost ではなく http://host.docker.internal:11434 を使います。ここは地味に間違えやすいポイントです。
補足:今回使った版では、Ollama のモデル名が登録フォームのドロップダウンに自動で出てきて、接続は特別な設定なしで通りました。版や環境によっては、Ollama 側を全インターフェース受け付け(
OLLAMA_HOST=0.0.0.0)にする必要が出る場合もあります。
結果:日本語RAG、ちゃんと動きました
最終構成(埋め込み:bge-m3 / LLM:gemini-2.5-flash)で、架空の社内ハンドブック(FAQ形式のサンプル)を取り込んで、日本語で質問してみました。結果は、ぜんぶ文書どおりの答えが返ってきました。
<!-- ▼ 画像④:取り込み成功の画面(おすすめ:16_20_04 / 中身プレビューが出て Parsing failed が消えたスクショ) -->
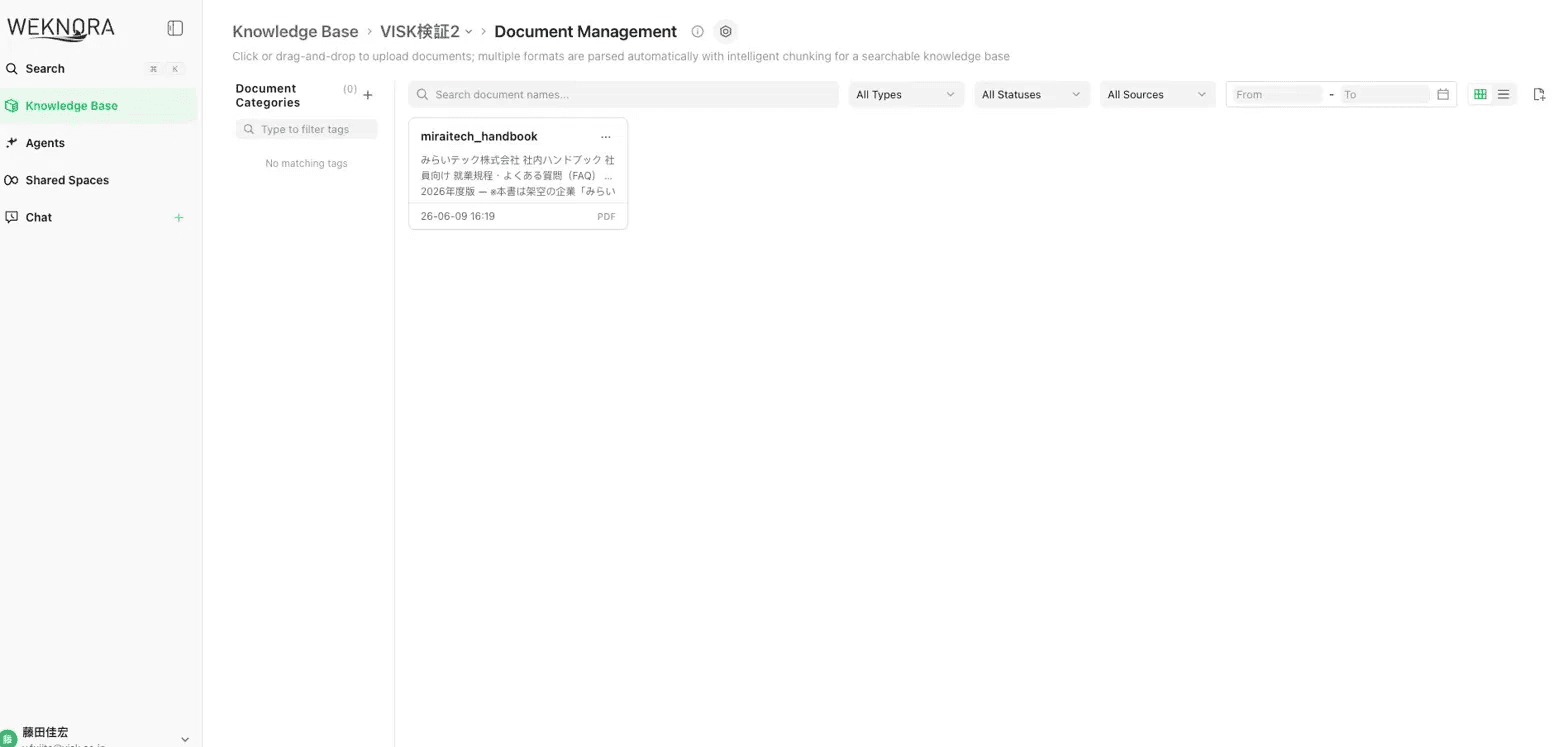
▲ 埋め込みをローカル Ollama にしたら、今度はあっさり成功(中身のプレビューが表示され、エラーが消えた)
質問 | 回答 | 文書の記載 |
|---|---|---|
夏季休暇は何日とれる? | 5日間 | 一致 |
リモートワークは週に何日まで? | 週最大3日 | 一致 |
経費の締め日はいつ? | 毎月25日 | 一致 |
健康診断はいつ実施される? | 年1回・毎年10月 | 一致 |
在宅勤務手当はいくら? | 月額3,000円 | 一致 |
ローカルの bge-m3 でも、日本語の意味をちゃんと拾って正しい答えを返してくれました。ここはシンプルに嬉しかったところです。
実際のやりとりを、順に貼っていきます。

▲ 最初の回答は中国語。「日本語で答えて」を添えると、以降は日本語で返ってくるように(夏季休暇は5日間)
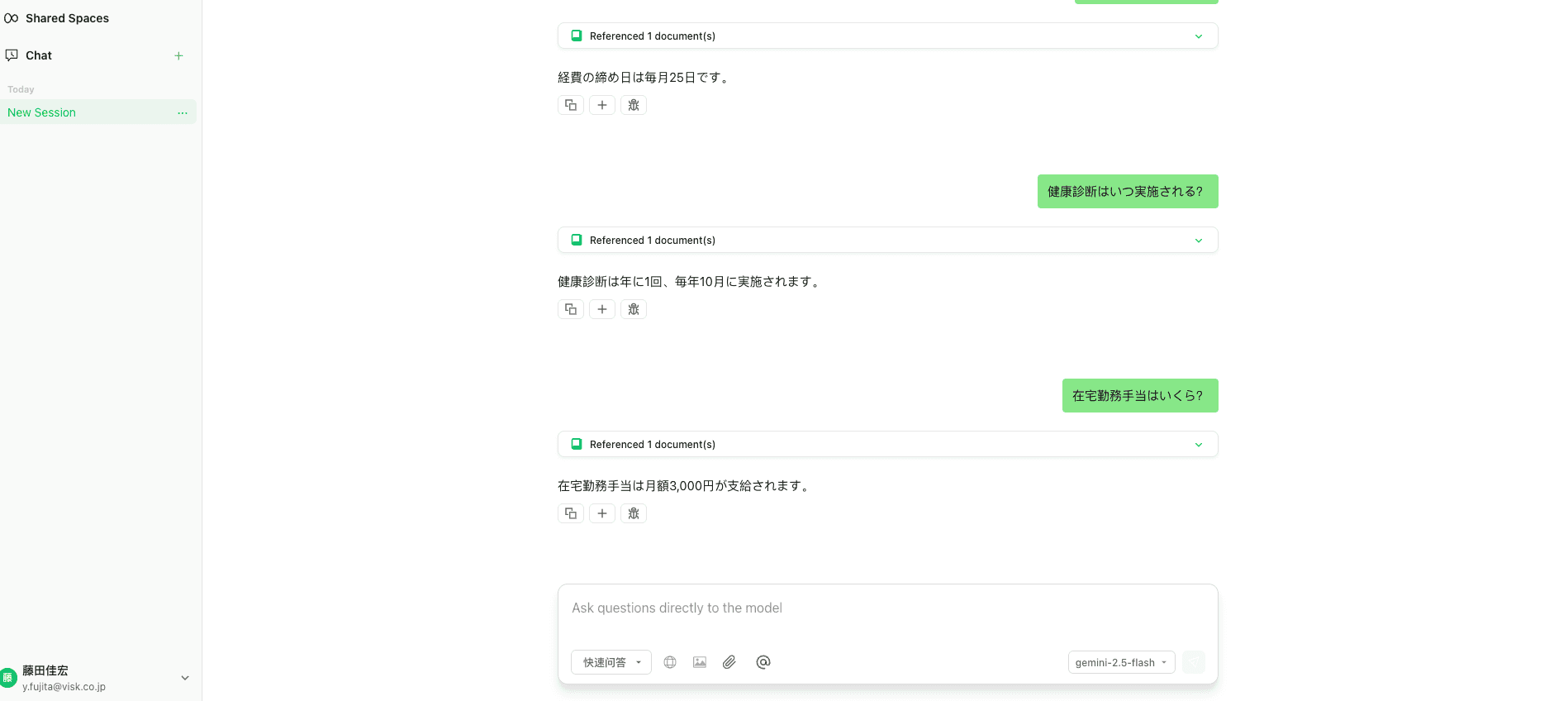
▲ 「月額3,000円」も正確に回答
ひとつだけ注意:回答の言語
ちょっと面白かったのが、最初の回答が中国語で返ってきたこと(上の1枚目)。WeKnora は内部のプロンプトが中国語ベースなので、それに引っ張られたのだと思います(画面の表示言語の設定とは別物です)。質問に「日本語で答えて」と添えると日本語に切り替わり、その後は同じ会話の中ではずっと日本語のままでした。常に日本語で使いたいなら、システムプロンプト側で言語を指定しておくのがよさそうです。
まとめ・ふりかえり
WeKnora 自体は導入は簡単。ただ、Gemini を OpenAI 互換エンドポイントで使うなら、埋め込みまわりに2つ落とし穴がある。
Base URL の末尾スラッシュで 404。
truncate_prompt_tokensの送信で 400(WeKnora 側の既知不具合。修正PRはあるが、検証時の:latestには入っていなかった)。
詰まったら、ログを「docreader(解析)」と「app(埋め込み)」に分けて見ると早い。404 なのか 400 なのか、メッセージのフィールド名まで読むと一気に原因に近づけます。
どうにもならないときは、埋め込みをローカル Ollama に逃がすのが確実。LLM はクラウドのまま使えるので、「埋め込みローカル+LLMクラウド」のハイブリッドは、データを外に出さない社内文書RAGとしてもけっこう理にかなっています。
回答の言語は中国語寄りがデフォルト。日本語で使うなら、プロンプトでの言語指定を前提にしておくと安心です。
この記事の数値やエラーは、検証時点で実際に確認したものです。WeKnora は更新が活発なので、
truncate_prompt_tokensの不具合は新しいイメージではもう直っているかもしれません。最新版で試すときは、まず Gemini 構成のまま取り込みが通るか確かめて、ダメだったらこの記事のローカル Ollama 構成に切り替える、という順番がおすすめです。
Tencent WeKnora を Gemini で動かしたら、embedding で2回ハマった話 ―― 404とtruncate_prompt_tokens、そしてローカルOllamaでの回避
Tencent が公開しているOSSのナレッジ基盤「WeKnora」を、社内文書RAGの検証用に手元の Mac で動かしてみました。
セットアップ自体はサクサク進んだのですが、「埋め込み(embedding)に Gemini を使う」ところで立て続けにつまずきました。原因にたどり着くまでにけっこう寄り道したので、その過程をそのまま残しておきます。同じ構成で同じところに引っかかる人がいたら、参考になればと思います。気軽に読んでもらえたら。
なお、ここに書いた内容はすべて検証時点で手元で再現したものです。WeKnora は更新が速いので、仕様が変わっていそうなところは都度ことわりを入れています。
検証した環境
マシン:Apple Silicon の Mac / メモリ 8GB
動かし方:Docker Compose(コア構成だけ。Neo4j や Langfuse まで入れるフル構成は、メモリの都合で今回は見送り)
WeKnora:検証時点の
:latestイメージ(途中で v0.6.1 に更新)最初に使おうとしたモデル
埋め込み:
gemini-embedding-001(Gemini API の OpenAI 互換エンドポイント経由)LLM:
gemini-2.5-flash
メモリ 8GB ということもあって、最初は「LLM も埋め込みも全部クラウド(Gemini)に任せよう」と考えていました。……が、この方針が後々の伏線になります。
つまずき①:embedding が 404 になる(犯人は末尾の /)
どうなったか
文書をアップロードすると、ステータスが 「Parsing failed」。あっさり失敗しました。
▲ アップロードした文書が軒並み「Parsing failed」。ここから原因の切り分けが始まりました
原因をどう絞ったか
まずは「解析(テキストを読み取る段階)」と「埋め込み(ベクトル化する段階)」のどっちでコケているのか、を切り分けました。
解析を担当する docreader のログを見ると、PDF も Markdown もテキスト抽出はちゃんと成功しています。
ということは、コケているのはその次の段階、app 側(チャンク分割と埋め込み)です。app のログを見たら、原因がはっきり書いてありました。
なぜ404だったか、どう直したか
404 は「そのURL、存在しませんよ」というサイン。Gemini の OpenAI 互換エンドポイントで embedding を叩くこと自体はできる(curl で直接叩くとちゃんと届く)のに、なぜか404。
犯人は、WeKnora に設定した Base URL の末尾に付けていた / でした。
設定していた値(NG):
https://generativelanguage.googleapis.com/v1beta/openai/直したあと(OK):
https://generativelanguage.googleapis.com/v1beta/openai
末尾スラッシュを外したら、エラーが 404 から 400 に変わりました。「URLが見つからない」状態は抜けて、リクエストがエンドポイントまで届くようになった、ということです。
ちょっと補足(ここは推測です):末尾に
/があると、WeKnora がURLを組み立てるときに.../openai//embeddingsのようにスラッシュが二重になって 404 になっていたのかな、と思っています。内部の挙動までは追っていないので推測どまりですが、「末尾スラッシュを外したら404が消えた」のは事実です。
つまずき②:今度は truncate_prompt_tokens で 400
どうなったか
404 は消えたのに、入れ替わりで今度はこれが出るように。
EmbedBatch API error: Http Status 400 Bad Request "Invalid JSON payload received. Unknown name \"truncate_prompt_tokens\"
なぜ起きるか
WeKnora の埋め込み処理が、リクエストに truncate_prompt_tokens というフィールドを乗せて送っていて、Gemini 側が「そんなフィールド知らない」とリクエストごと突き返していた、というのが原因です。
調べてみたら、これは WeKnora 側の既知の不具合で、リリースノートにこんな修正が載っていました。
fix(embedding): remove hardcoded TruncatePromptTokens in BatchEmbed
「BatchEmbed にハードコードされていた TruncatePromptTokens を取り除く」という修正です。コードに直接埋め込まれていた値なので、設定画面から無効化する、という逃げ方はできませんでした。
修正版に上げようとしたものの……
直っているはずの新しい版に上げようと、本体を更新しました。
git pull docker compose pull docker compose up -d
ソースは v0.6.1 まで上がったのですが、docker compose pull で取ってきた :latest イメージにはまだ修正が入っておらず、同じ 400 がそのまま再発しました。ここはちょっと拍子抜けでした。
補足(推測):公開イメージがソースの修正に追いついていなかったか、修正が当該タグにまだ含まれていなかったか、のどちらかだと思います。そこまでは確認できていません。確実なのは「更新後も
:latestでは同じエラーが出た」という結果だけです。ソースから自前でビルドする方法は、今回は試していません。
抜け道:埋め込みだけ、ローカルの Ollama に逃がす
Gemini 経由の埋め込みがバグで止まってしまうので、思い切って埋め込みだけをローカルの Ollama に切り替え、LLM はクラウドの Gemini のまま残すことにしました。埋め込みモデルは LLM に比べてずっと軽いので、メモリ 8GB でも「埋め込みだけなら」十分動かせる、という読みです。
やったことの要点
Ollama を入れる(Homebrew 版はインストールでつまずきました。
llama-serverのバイナリが見つからず推論できなかったので、公式アプリ版に切り替え)日本語に強い埋め込みモデルを取得
WeKnora に Ollama 埋め込みモデルを登録
Source:Ollama (Local)
Model:
bge-m3Vector Dimension:
1024
既存のナレッジベースは旧モデルで作っていたので、埋め込みを
bge-m3にして作り直し
▲ Source を「Ollama (Local)」にして bge-m3 を登録。次元は 1024
▲ ナレッジベースを作り直し、埋め込みに bge-m3、LLM に gemini-2.5-flash を指定
Docker からホストの Ollama に繋ぐときの小さな罠
WeKnora は Docker コンテナの中で動いているので、コンテナから見た localhost は「コンテナ自身」を指してしまいます。ホストの Mac で動いている Ollama に繋ぐには、localhost ではなく http://host.docker.internal:11434 を使います。ここは地味に間違えやすいポイントです。
補足:今回使った版では、Ollama のモデル名が登録フォームのドロップダウンに自動で出てきて、接続は特別な設定なしで通りました。版や環境によっては、Ollama 側を全インターフェース受け付け(
OLLAMA_HOST=0.0.0.0)にする必要が出る場合もあります。
結果:日本語RAG、ちゃんと動きました
最終構成(埋め込み:bge-m3 / LLM:gemini-2.5-flash)で、架空の社内ハンドブック(FAQ形式のサンプル)を取り込んで、日本語で質問してみました。結果は、ぜんぶ文書どおりの答えが返ってきました。
<!-- ▼ 画像④:取り込み成功の画面(おすすめ:16_20_04 / 中身プレビューが出て Parsing failed が消えたスクショ) -->
▲ 埋め込みをローカル Ollama にしたら、今度はあっさり成功(中身のプレビューが表示され、エラーが消えた)
質問 | 回答 | 文書の記載 |
|---|---|---|
夏季休暇は何日とれる? | 5日間 | 一致 |
リモートワークは週に何日まで? | 週最大3日 | 一致 |
経費の締め日はいつ? | 毎月25日 | 一致 |
健康診断はいつ実施される? | 年1回・毎年10月 | 一致 |
在宅勤務手当はいくら? | 月額3,000円 | 一致 |
ローカルの bge-m3 でも、日本語の意味をちゃんと拾って正しい答えを返してくれました。ここはシンプルに嬉しかったところです。
実際のやりとりを、順に貼っていきます。
▲ 最初の回答は中国語。「日本語で答えて」を添えると、以降は日本語で返ってくるように(夏季休暇は5日間)
▲ 「月額3,000円」も正確に回答
ひとつだけ注意:回答の言語
ちょっと面白かったのが、最初の回答が中国語で返ってきたこと(上の1枚目)。WeKnora は内部のプロンプトが中国語ベースなので、それに引っ張られたのだと思います(画面の表示言語の設定とは別物です)。質問に「日本語で答えて」と添えると日本語に切り替わり、その後は同じ会話の中ではずっと日本語のままでした。常に日本語で使いたいなら、システムプロンプト側で言語を指定しておくのがよさそうです。
まとめ・ふりかえり
WeKnora 自体は導入は簡単。ただ、Gemini を OpenAI 互換エンドポイントで使うなら、埋め込みまわりに2つ落とし穴がある。
Base URL の末尾スラッシュで 404。
truncate_prompt_tokensの送信で 400(WeKnora 側の既知不具合。修正PRはあるが、検証時の:latestには入っていなかった)。
詰まったら、ログを「docreader(解析)」と「app(埋め込み)」に分けて見ると早い。404 なのか 400 なのか、メッセージのフィールド名まで読むと一気に原因に近づけます。
どうにもならないときは、埋め込みをローカル Ollama に逃がすのが確実。LLM はクラウドのまま使えるので、「埋め込みローカル+LLMクラウド」のハイブリッドは、データを外に出さない社内文書RAGとしてもけっこう理にかなっています。
回答の言語は中国語寄りがデフォルト。日本語で使うなら、プロンプトでの言語指定を前提にしておくと安心です。
この記事の数値やエラーは、検証時点で実際に確認したものです。WeKnora は更新が活発なので、
truncate_prompt_tokensの不具合は新しいイメージではもう直っているかもしれません。最新版で試すときは、まず Gemini 構成のまま取り込みが通るか確かめて、ダメだったらこの記事のローカル Ollama 構成に切り替える、という順番がおすすめです。

AI・システム開発のこと、VISKにご相談ください
「自社の業務にAIを活かせないか」「この作業、自動化できないか」——
そんな漠然とした段階からで大丈夫です。大阪のAI・システム開発会社VISKが、御社の課題に合わせて、企画から開発・検証までサポートします。
