「Fugu UltraはFable 5やMythosと同等」って本当? ── 単体Opus 4.8とコーディングで勝負させてみた
「Fugu UltraはFable 5やMythosと同等」って本当? ── 単体Opus 4.8とコーディングで勝負させてみた

はじめに
2026年6月、Sakana AIから「魚」の名前がついたプロダクトがいくつか登場しました。今回はまず、公開されている3つ ── Sakana Fugu / Sakana Chat / Sakana Marlin ── をさらっと紹介したうえで、そのなかの Sakana Fugu(くわしくは上位モデルの Fugu Ultra)を実際に動かして、ある気になる主張をたしかめてみます。
前半の製品紹介は各製品の公式ページ(公開情報)をもとにしています。性能の数値は各社が公表しているもので、後半でお見せするのは、あくまで私たちが手元で実際に試した範囲のお話です。
Sakana AIの3つのプロダクト
Sakana Fugu ── たくさんのモデルを「1つのモデル」みたいに使えるAPI
Sakana Fuguは、複数のモデルをうまく組み合わせ、協力させながら難しいタスクを解いていく、という発想のプロダクトです。公式の説明によると、得意分野のちがうモデルたちを1つのAPIから呼び出せて、「どのモデルに任せるか」はFuguが自動で決めてくれるそうです。OpenAI互換APIなので、今使っているクライアントやコーディングツールにそのまま差し込める、という手軽さも売りになっています。
モデルは2種類あります。標準の Fugu は性能と速さのバランス型、Fugu Ultra は時間がかかっても答えの質を優先する、じっくり考えるタイプです。技術的には、モデルの連携を「学習」で実現する研究(ICLR 2026の論文「TRINITY」「Conductor」)がベースになっているとのこと。今回主役になるのは、このFugu Ultraです。
Sakana Chat ── チャットアプリ
Sakana Chatは、Sakana AIが出しているチャットアプリです。公開ページの情報がかぎられているので、ここでは紹介だけにとどめておきます。
Sakana Marlin ── 自分で動く調査エージェント
Sakana Marlinは、「Virtual CSO(最高戦略責任者)」をうたう、自律型のリサーチエージェントです。テーマを渡すと最大8時間も自分で考えつづけて、戦略レポートまで仕上げてくれる、と紹介されています。経営層やコンサルなど、深い調査が必要な場面を想定したプロダクトのようです。
きっかけ:「Fable 5やMythosと同等」ってホント?
今回の出発点は、Fugu Ultraについてのこんな主張でした。
Fugu Ultraは、エンジニアリング・科学・推論のベンチマークで、AnthropicのFable 5やMythos Previewに比肩する。
なかなかインパクトのある言葉です。でも、いざ検証しようとしたら、最初の一歩でつまずきました。
じつは、Fable 5とMythos Previewは、輸出規制のせいで一般には使えません。 つまり、この2つを直接呼び出して比べることが、そもそもできないんです。これはSakana自身も認めていて、両モデルはFugu Ultraの内部チームにも入っていない、とはっきり書かれています。
しかも、公開されているスコアは各社が自分で測った申告値(provider-reported)を横にならべたもので、Sakanaが同じ条件で測り直した「直接対決」の結果ではありません。一部のSWE系タスクは「mini-swe-agent」という特定の足場を使った数字で、全モデルで条件がそろっているとも限らないようです。
ようするに、「Fugu Ultra = Fable 5/Mythos」という言葉は、ガチンコ対決の結果というより、自己申告スコアをならべて見せたもの、と受け取っておくのがよさそうです。
検証の作戦:得意分野のコーディングで、中の単体モデルと戦わせる
Fable 5を直接呼べない以上、別の角度から攻めることにしました。ヒントになったのは、Sakanaのもう1つの主張です。
オーケストレーター(Fugu)は、自分が束ねている個々のモデルよりも強い。
Fugu Ultraは、中でOpus 4.8やGPT-5.5、Gemini 3.1 Proといった公開モデルをうまく振り分けて使っている、とされています。それなら、「みんなで協力するFugu Ultraは、その中にいる一番強い単体モデルに、本当に勝てるのか?」 を手元で試せます。しかもコーディングはFuguの得意分野。まさに本丸での勝負です。
やり方はこんな感じです。
お題:単体モデルがついうっかり見落としそうな「ちょっとひねった複合バグ」入りのPython関数を5問用意(あとで紹介します)
対戦カード:同じバグ入りコードを Fugu Ultra と 単体 Opus 4.8 にそれぞれ直してもらう
採点:仕様だけを渡して(答え合わせ用のテストは見せません)、直したコードを隠しテストにかけて○×をつける
回数:1問あたり3回ずつ(合計15回)。ブレ具合も見ます
記録:かかった時間、トークン量、コスト(Fugu Ultraは後で出てくる「裏のトークン」込み)
用意した5問はこちらです。どれも「ぱっと見は動くけど、ある入力でこっそり壊れる」タイプのバグです。
LRUキャッシュ ── 「最近使ったか」を追えていない
レート制限 ── 境界の数えまちがい+いつもTrueを返してしまう
区間マージ ── 並んでいない入力を想定していない+元のリストを壊してしまう
ページネーション ── 切り上げのミス+ページ番号のずれ+入力チェック忘れ
JSONフラット化 ── 空っぽの辞書
{}をそのまま残す処理が抜けている
ちなみに採点する仕組みのほうは、事前に「バグ版はちゃんと×になる/正解版はちゃんと○になる」ことを確認ずみです。お題と採点基準は、フェアにするために公開しています。
結果①:正答率 ── 単体Opusのほうが上でした
まずは正答率から。さきに結果を言ってしまうと、3回ずつ(合計15回)の集計はこうなりました。
Fugu Ultra:13/15(86.7%)
Opus 4.8:15/15(100%)
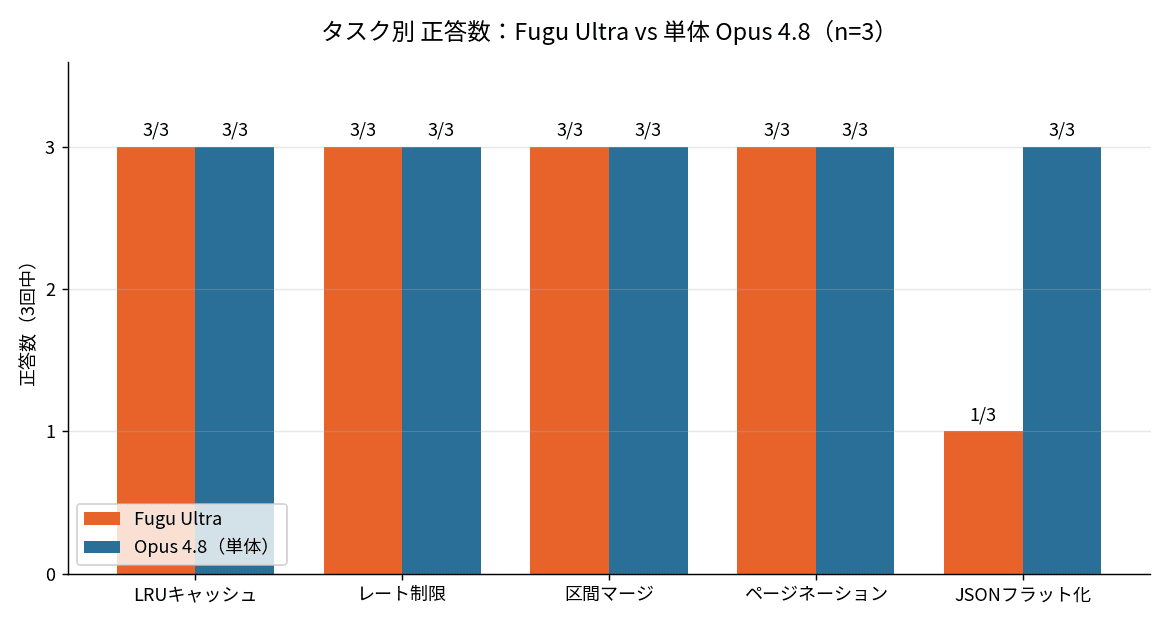
5問のうち4問は、どちらも安定して正解。差がついたのは1問だけ、JSONフラット化でした。Opus 4.8は3回とも正解しましたが、Fugu Ultraは3回中2回つまずいています。「協力するほうが強いはず」という期待とは、ちょっと逆の結果になりました。
結果②:速度とコスト ── 見えていなかった「裏の出費」
速度はわかりやすかったです。Opus 4.8が1問あたり平均2.6秒だったのに対して、Fugu Ultraは平均24.5秒。だいたい10倍かかっています。中でいくつものモデルを動かしているので、まあこれは想定どおりです。
ややこしかったのはコストのほうでした。じつはここで、私たちは一度検証をやり直しています。
最初はOpenAI互換のChat Completions APIでトークンを数えていて、その数字だと「FuguとOpusはほぼ互角」という結果でした。でも、これはまちがいだったんです。
Fugu Ultraは、中で複数のモデルに仕事を振って、答え合わせをして、まとめあげます。その過程で使う orchestrationトークン(裏で動く分のトークン) は、表に見えるinput/outputとは別に発生して、しかもちゃんと料金に乗ってきます。やっかいなことに、この裏のトークンはResponses APIでないと取得できず、Chat Completionsでは取りこぼしていました。
そこでResponses APIに切り替えて測り直したら、ようやく本当の姿が見えました。

Fugu Ultraの15回ぶんで、表のトークンは合計3,000ちょっと。ところが裏のorchestrationトークンは合計109,220もありました。表だけで計算すると約$0.24だったのに、裏まで含めた実コストは約$1.04 ── ざっと4.4倍です。いっぽうOpus 4.8には裏のトークンがないので、表の数字がそのまま実コストでした。
もし表のトークンだけでコストを語っていたら、「コストは互角」というまちがった結論を出してしまうところでした。マルチエージェント型のモデルを評価するときは、この「裏の出費」をかならず数えておかないといけませんね。
結果③:JSONフラット化で見えた「気分屋」な一面
差がついた唯一の問題、JSONフラット化をもう少しのぞいてみます。この問題のお題は「空っぽの辞書 {} はそのまま葉として残す(例:{'a': {}} → {'a': {}})」というものでした。
Fugu Ultraの3回は、こんな感じでした。
1回目(×):空辞書を見つけると
out[key] = '空辞書'── なぜか「空辞書」という文字列を入れてしまった2回目(×):またしても
out[key] = '空辞書'── 同じまちがいをくり返す3回目(○):
if isinstance(v, dict) and v:── 空辞書をうまくよけて、{}をそのまま残す正しい形にやっとたどり着いた
いっぽうOpus 4.8は、3回とも一発で and v の正しい書き方。しかも3回ともほぼ同じコードでした。
つまりFugu Ultraは、お題の「葉として残す」を「『空辞書』という文字を入れる」と読みちがえて、しかも毎回ちょっとずつ解釈がブレて、3回目でようやく正解にたどり着いた、というわけです。実行のたびに中のモデルの選び方や連携が変わる、というマルチエージェントの性格が、コードにそのまま出てしまったサンプルでした。「単体モデルの安定感」と「みんなで動くからこその気分屋っぽさ」の対比が、くっきり出た一件です。
公表ベンチとも照らし合わせてみる
最後に、もとの主張のベースになっているSakanaの公表ベンチマークも見ておきます。くりかえしになりますが、これは各社の自己申告値で、Fable 5は規制で直接たしかめられない点には注意が必要です。
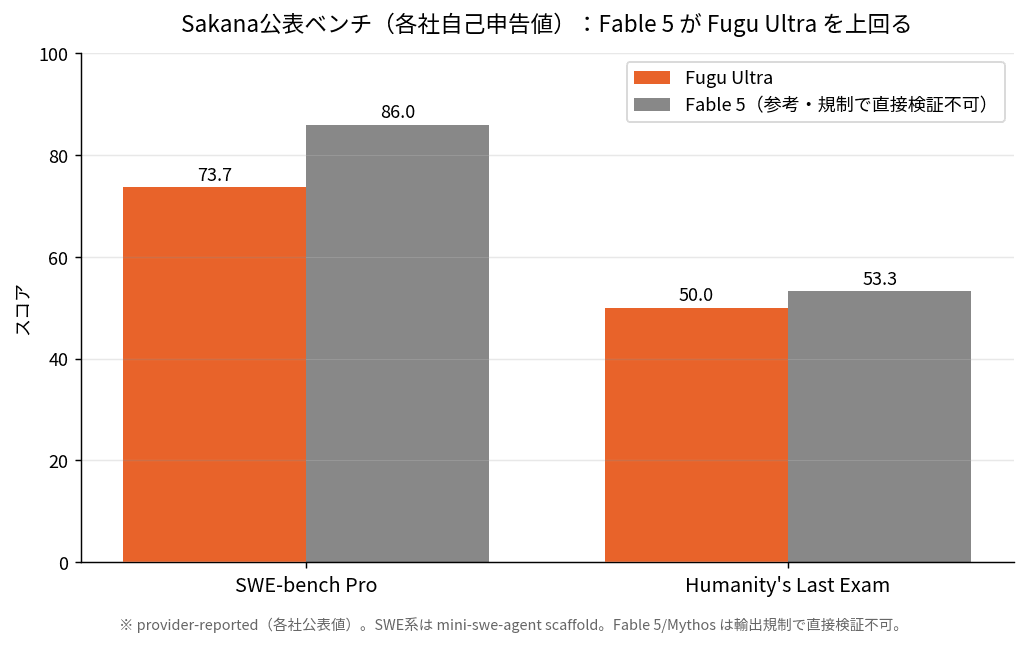
Sakanaの技術レポートのスコアを見ると、たとえばSWE-bench ProではFable 5が86.0でFugu Ultraが73.7、Humanity's Last ExamでもFable 5が53.3でFugu Ultraが50.0。つまり公表値の上でも、これらの項目ではFable 5のほうが上なんですね。「比肩する(shoulder-to-shoulder)」という言い方は、ベンチごとに勝ったり負けたりするなかでの「全体としては近い」という意味であって、「全項目で同じ」という話ではなさそうです。
おわりに
今回わかったことを、ゆるくまとめてみます。
私たちが手元で試せた範囲(自前のコーディング・バグ修正、3回ずつ)では、単体のOpus 4.8が、正答率・速度・コストのぜんぶでFugu Ultraを上回りました。正答率は15/15対13/15、速度は約10倍速、コストは裏のトークンまで入れると約4分の1。とくにJSONフラット化で見えた「毎回ちょっとブレる」感じは、マルチエージェントならではの不安定さを、わかりやすく見せてくれました。
とはいえ、これは「Fugu Ultraがダメ」という話ではありません。今回のお題は、強い単体モデルなら一発で解けるくらいの難しさで、Fuguが本領を発揮するという「長くて、ごちゃっとした、何段階もあるワークフロー」とは性質がちがいます。そういうタスクなら協力プレイの良さが出るかもしれず、そこはまた別の機会にたしかめてみたいところです。
最初の「Fable 5やMythosと同等なの?」という問いには、こう答えられそうです。あれはガチンコ対決の結果ではなく自己申告スコアのならびで、公表値の上でもFable 5が上回る項目はある。実際のタスクでの強さはお題しだいで、Fugu Ultraを使うなら「裏で膨らむコスト」と「答えの安定感」には気をつけておきたい ── 手を動かして出した、今回の結論です。
検証環境:Fugu Ultra(fugu-ultra-20260615、Responses API、reasoning effort=high)、Claude Opus 4.8。コストはFugu Ultra入力$5/出力$30(per 1Mトークン、272Kコンテキスト以下)で計算。Opus 4.8のレートは暫定値のため、正確なコストは最新の公式レートで再計算してください。ベンチマーク値はSakana技術レポートおよび各社公表値(provider-reported)にもとづきます。
はじめに
2026年6月、Sakana AIから「魚」の名前がついたプロダクトがいくつか登場しました。今回はまず、公開されている3つ ── Sakana Fugu / Sakana Chat / Sakana Marlin ── をさらっと紹介したうえで、そのなかの Sakana Fugu(くわしくは上位モデルの Fugu Ultra)を実際に動かして、ある気になる主張をたしかめてみます。
前半の製品紹介は各製品の公式ページ(公開情報)をもとにしています。性能の数値は各社が公表しているもので、後半でお見せするのは、あくまで私たちが手元で実際に試した範囲のお話です。
Sakana AIの3つのプロダクト
Sakana Fugu ── たくさんのモデルを「1つのモデル」みたいに使えるAPI
Sakana Fuguは、複数のモデルをうまく組み合わせ、協力させながら難しいタスクを解いていく、という発想のプロダクトです。公式の説明によると、得意分野のちがうモデルたちを1つのAPIから呼び出せて、「どのモデルに任せるか」はFuguが自動で決めてくれるそうです。OpenAI互換APIなので、今使っているクライアントやコーディングツールにそのまま差し込める、という手軽さも売りになっています。
モデルは2種類あります。標準の Fugu は性能と速さのバランス型、Fugu Ultra は時間がかかっても答えの質を優先する、じっくり考えるタイプです。技術的には、モデルの連携を「学習」で実現する研究(ICLR 2026の論文「TRINITY」「Conductor」)がベースになっているとのこと。今回主役になるのは、このFugu Ultraです。
Sakana Chat ── チャットアプリ
Sakana Chatは、Sakana AIが出しているチャットアプリです。公開ページの情報がかぎられているので、ここでは紹介だけにとどめておきます。
Sakana Marlin ── 自分で動く調査エージェント
Sakana Marlinは、「Virtual CSO(最高戦略責任者)」をうたう、自律型のリサーチエージェントです。テーマを渡すと最大8時間も自分で考えつづけて、戦略レポートまで仕上げてくれる、と紹介されています。経営層やコンサルなど、深い調査が必要な場面を想定したプロダクトのようです。
きっかけ:「Fable 5やMythosと同等」ってホント?
今回の出発点は、Fugu Ultraについてのこんな主張でした。
Fugu Ultraは、エンジニアリング・科学・推論のベンチマークで、AnthropicのFable 5やMythos Previewに比肩する。
なかなかインパクトのある言葉です。でも、いざ検証しようとしたら、最初の一歩でつまずきました。
じつは、Fable 5とMythos Previewは、輸出規制のせいで一般には使えません。 つまり、この2つを直接呼び出して比べることが、そもそもできないんです。これはSakana自身も認めていて、両モデルはFugu Ultraの内部チームにも入っていない、とはっきり書かれています。
しかも、公開されているスコアは各社が自分で測った申告値(provider-reported)を横にならべたもので、Sakanaが同じ条件で測り直した「直接対決」の結果ではありません。一部のSWE系タスクは「mini-swe-agent」という特定の足場を使った数字で、全モデルで条件がそろっているとも限らないようです。
ようするに、「Fugu Ultra = Fable 5/Mythos」という言葉は、ガチンコ対決の結果というより、自己申告スコアをならべて見せたもの、と受け取っておくのがよさそうです。
検証の作戦:得意分野のコーディングで、中の単体モデルと戦わせる
Fable 5を直接呼べない以上、別の角度から攻めることにしました。ヒントになったのは、Sakanaのもう1つの主張です。
オーケストレーター(Fugu)は、自分が束ねている個々のモデルよりも強い。
Fugu Ultraは、中でOpus 4.8やGPT-5.5、Gemini 3.1 Proといった公開モデルをうまく振り分けて使っている、とされています。それなら、「みんなで協力するFugu Ultraは、その中にいる一番強い単体モデルに、本当に勝てるのか?」 を手元で試せます。しかもコーディングはFuguの得意分野。まさに本丸での勝負です。
やり方はこんな感じです。
お題:単体モデルがついうっかり見落としそうな「ちょっとひねった複合バグ」入りのPython関数を5問用意(あとで紹介します)
対戦カード:同じバグ入りコードを Fugu Ultra と 単体 Opus 4.8 にそれぞれ直してもらう
採点:仕様だけを渡して(答え合わせ用のテストは見せません)、直したコードを隠しテストにかけて○×をつける
回数:1問あたり3回ずつ(合計15回)。ブレ具合も見ます
記録:かかった時間、トークン量、コスト(Fugu Ultraは後で出てくる「裏のトークン」込み)
用意した5問はこちらです。どれも「ぱっと見は動くけど、ある入力でこっそり壊れる」タイプのバグです。
LRUキャッシュ ── 「最近使ったか」を追えていない
レート制限 ── 境界の数えまちがい+いつもTrueを返してしまう
区間マージ ── 並んでいない入力を想定していない+元のリストを壊してしまう
ページネーション ── 切り上げのミス+ページ番号のずれ+入力チェック忘れ
JSONフラット化 ── 空っぽの辞書
{}をそのまま残す処理が抜けている
ちなみに採点する仕組みのほうは、事前に「バグ版はちゃんと×になる/正解版はちゃんと○になる」ことを確認ずみです。お題と採点基準は、フェアにするために公開しています。
結果①:正答率 ── 単体Opusのほうが上でした
まずは正答率から。さきに結果を言ってしまうと、3回ずつ(合計15回)の集計はこうなりました。
Fugu Ultra:13/15(86.7%)
Opus 4.8:15/15(100%)
5問のうち4問は、どちらも安定して正解。差がついたのは1問だけ、JSONフラット化でした。Opus 4.8は3回とも正解しましたが、Fugu Ultraは3回中2回つまずいています。「協力するほうが強いはず」という期待とは、ちょっと逆の結果になりました。
結果②:速度とコスト ── 見えていなかった「裏の出費」
速度はわかりやすかったです。Opus 4.8が1問あたり平均2.6秒だったのに対して、Fugu Ultraは平均24.5秒。だいたい10倍かかっています。中でいくつものモデルを動かしているので、まあこれは想定どおりです。
ややこしかったのはコストのほうでした。じつはここで、私たちは一度検証をやり直しています。
最初はOpenAI互換のChat Completions APIでトークンを数えていて、その数字だと「FuguとOpusはほぼ互角」という結果でした。でも、これはまちがいだったんです。
Fugu Ultraは、中で複数のモデルに仕事を振って、答え合わせをして、まとめあげます。その過程で使う orchestrationトークン(裏で動く分のトークン) は、表に見えるinput/outputとは別に発生して、しかもちゃんと料金に乗ってきます。やっかいなことに、この裏のトークンはResponses APIでないと取得できず、Chat Completionsでは取りこぼしていました。
そこでResponses APIに切り替えて測り直したら、ようやく本当の姿が見えました。
Fugu Ultraの15回ぶんで、表のトークンは合計3,000ちょっと。ところが裏のorchestrationトークンは合計109,220もありました。表だけで計算すると約$0.24だったのに、裏まで含めた実コストは約$1.04 ── ざっと4.4倍です。いっぽうOpus 4.8には裏のトークンがないので、表の数字がそのまま実コストでした。
もし表のトークンだけでコストを語っていたら、「コストは互角」というまちがった結論を出してしまうところでした。マルチエージェント型のモデルを評価するときは、この「裏の出費」をかならず数えておかないといけませんね。
結果③:JSONフラット化で見えた「気分屋」な一面
差がついた唯一の問題、JSONフラット化をもう少しのぞいてみます。この問題のお題は「空っぽの辞書 {} はそのまま葉として残す(例:{'a': {}} → {'a': {}})」というものでした。
Fugu Ultraの3回は、こんな感じでした。
1回目(×):空辞書を見つけると
out[key] = '空辞書'── なぜか「空辞書」という文字列を入れてしまった2回目(×):またしても
out[key] = '空辞書'── 同じまちがいをくり返す3回目(○):
if isinstance(v, dict) and v:── 空辞書をうまくよけて、{}をそのまま残す正しい形にやっとたどり着いた
いっぽうOpus 4.8は、3回とも一発で and v の正しい書き方。しかも3回ともほぼ同じコードでした。
つまりFugu Ultraは、お題の「葉として残す」を「『空辞書』という文字を入れる」と読みちがえて、しかも毎回ちょっとずつ解釈がブレて、3回目でようやく正解にたどり着いた、というわけです。実行のたびに中のモデルの選び方や連携が変わる、というマルチエージェントの性格が、コードにそのまま出てしまったサンプルでした。「単体モデルの安定感」と「みんなで動くからこその気分屋っぽさ」の対比が、くっきり出た一件です。
公表ベンチとも照らし合わせてみる
最後に、もとの主張のベースになっているSakanaの公表ベンチマークも見ておきます。くりかえしになりますが、これは各社の自己申告値で、Fable 5は規制で直接たしかめられない点には注意が必要です。
Sakanaの技術レポートのスコアを見ると、たとえばSWE-bench ProではFable 5が86.0でFugu Ultraが73.7、Humanity's Last ExamでもFable 5が53.3でFugu Ultraが50.0。つまり公表値の上でも、これらの項目ではFable 5のほうが上なんですね。「比肩する(shoulder-to-shoulder)」という言い方は、ベンチごとに勝ったり負けたりするなかでの「全体としては近い」という意味であって、「全項目で同じ」という話ではなさそうです。
おわりに
今回わかったことを、ゆるくまとめてみます。
私たちが手元で試せた範囲(自前のコーディング・バグ修正、3回ずつ)では、単体のOpus 4.8が、正答率・速度・コストのぜんぶでFugu Ultraを上回りました。正答率は15/15対13/15、速度は約10倍速、コストは裏のトークンまで入れると約4分の1。とくにJSONフラット化で見えた「毎回ちょっとブレる」感じは、マルチエージェントならではの不安定さを、わかりやすく見せてくれました。
とはいえ、これは「Fugu Ultraがダメ」という話ではありません。今回のお題は、強い単体モデルなら一発で解けるくらいの難しさで、Fuguが本領を発揮するという「長くて、ごちゃっとした、何段階もあるワークフロー」とは性質がちがいます。そういうタスクなら協力プレイの良さが出るかもしれず、そこはまた別の機会にたしかめてみたいところです。
最初の「Fable 5やMythosと同等なの?」という問いには、こう答えられそうです。あれはガチンコ対決の結果ではなく自己申告スコアのならびで、公表値の上でもFable 5が上回る項目はある。実際のタスクでの強さはお題しだいで、Fugu Ultraを使うなら「裏で膨らむコスト」と「答えの安定感」には気をつけておきたい ── 手を動かして出した、今回の結論です。
検証環境:Fugu Ultra(fugu-ultra-20260615、Responses API、reasoning effort=high)、Claude Opus 4.8。コストはFugu Ultra入力$5/出力$30(per 1Mトークン、272Kコンテキスト以下)で計算。Opus 4.8のレートは暫定値のため、正確なコストは最新の公式レートで再計算してください。ベンチマーク値はSakana技術レポートおよび各社公表値(provider-reported)にもとづきます。
